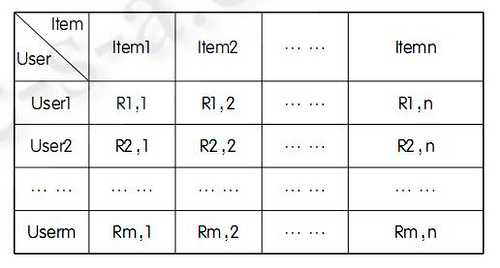

余弦相似性
余弦相似性 通过测量两个向量内积空间的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个 向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为 0;两个向量指向完全相反的方向时,余弦相似度的值为-1。在比较过程中,向量的规模大小不予考虑,仅仅考虑到向量的指向方向。余弦相似度通常用于两个向 量的夹角小于90°之内,因此余弦相似度的值为0到1之间。
值得注意的是余弦相似度可以用在任何维度的向量比较中,它尤其在高维正空间中的利用尤为频繁。例如在信息检索中,每个词条拥有不同的度,一个文档是 由一个由有权值的特征向量表示的,权值的计算取决于词条在该文档中出现的频率。余弦相似度因此可以给出两篇文档其主题方面的相似度。
另外,它通常用于文本挖掘中的文件比较。此外,在数据挖掘领域中,用它来衡量集群内部的凝聚力。[1]
定义
两个向量间的余弦值可以很容易地通过使用欧几里得点积和量级公式推导:
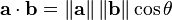
鉴于两个向量的属性, A 和B的余弦相似性θ用一个点积形式来表示其大小,如下所示:
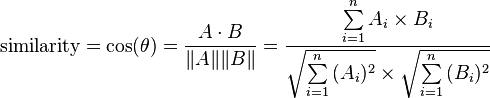
产生的相似性范围从-1到1:-1意味着两个向量指向的方向正好截然相反,1表示它们的指向是完全相同的,0通常表示它们之间是独立的,而在这之间的值则表示中度的相似性或相异性。 对于文本匹配,属性向量A 和B 通常是文档中的词频向量。余弦相似性,可以被看作是一个规范比较文件长度的方法。 在信息检索的情况下,由于一个词的频率(TF-IDF权)不能为负数,所以这两个文档的余弦相似性范围从0到1。并且,两个词的频率向量之间的角度不能大于90°。
角的相似性
“余弦相似性” 有时也被用来表达不同的系数,但最常见的是像上述定义那样的。同相似性的计算方法相似,向量之间规范化的的角度可以作为一个范围在[0,1]上的有界相似性函数,从上述定义的相似性计算方法如下: 
在这一公式中,向量系数可能是正,也可能是负,或者 
而在这一式子中,向量系数总是正的。 虽然 “余弦相似性” 一词已用于角距离,但是它很奇妙地仅作为一种计算角度的简便方法而本身并无此意思。角的相似系数的优点是,当作为一个差异系数(从1减去它)时,在不为第 一要义的情况下,产生的功能是一个适当的距离矩阵。然而,对于大多数的用途,这不是一个重要的属性。对于任何用途,只有在一组向量的相似性或距离的相对顺 序是很重要的,那么该函数在产生顺序时受选择的影响是无关紧要的。
“塔尼莫特”系数的困惑
有时,余弦相似性作为特殊形式的相似系数和如下类似的代数形式相混淆了:

事实上,这个代数形式在计算Jaccard系数时以位向量作为被比较的集的机制首次被塔尼莫特定义。虽然公式扩展到一般的向量,它具有和余弦相似完全不同的性质,并且承担重要的关系。
落和系数
这个系数在在生物学中也叫落合系数或落合Barkman系数[2][3]: 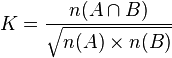
另见
- 索伦森的智商的相似性
- 海明距离
- 相关性
- 骰子的系数
- Jaccard指数
- SimRank
- 信息检索
外部链接
- 加权的余弦措施
- http://www.miislita.com/information-retrieval-tutorial/cosine-similarity-tutorial.html#Cosim
参考文献
- ^ P.-N. Tan, M. Steinbach & V. Kumar, “Introduction to Data Mining”, , Addison-Wesley (2005), ISBN 0-321-32136-7, chapter 8; page 500.
- ^ Ochiai A. Zoogeographical studies on the soleoid fishes found Japan and its neighboring regions. II // Bull. Jap. Soc. sci. Fish. 1957. V. 22. № 9. P. 526-530.
- ^ Barkman J.J. Phytosociology and ecology of cryptogamic epiphytes, including a taxonomic survey and description of their vegetation units in Europe. – Assen. Van Gorcum. 1958. 628 p.
YouTube转向Amazon的推荐算法
Greg Linden,亚马逊早期推荐系统的主要贡献者,在最近的博文《YouTube uses Amazon’s recommendation algorithm》中讨论了YouTube在RecSys 2010上的一篇论文,因为该文报告,目前YouTube的推荐算法主要采用Item-based方法和Ranking方法。
YouTube在WWW 2008上 曾经报告过他们使用Random Walk方法解决视频推荐问题的研究结果。我不是很适应这篇文章的表述方式,虽然自问对Random Walk方法多少还是有点了解,但一直没弄清楚他们的方法在变化万千的图方法中到底该归于哪一类,所以没法做什么有意义的讨论,不过我们在其他领域使用图 方法总的来说效果还是不错的。现在YouTube报告采用Item-based方法,或许说明他们对Random Walk方法的尝试并不成功。
Greg Linden早在1998年就已经使用Item-based方法解决推荐问题,对这个情况自然会很感兴趣,他在博文中写道:“Item-to-item collaborative filtering is the algorithm Amazon developed back in 1998. Over a decade later, it appears YouTube found a variation of Amazon’s algorithm to be the best for their video recommendations.” 我在以前的博文中 提到过,Item-Based方法总体来说是一种heurestic方法,对目标的拟合能力有限。但是另一方面,如果我们把推荐看成是一个检索问题,还是 能找到很多改进方法的。其实检索领域使用的tf/idf或者bm 25等方法也是一些heurestic方法,但把多个heurestic方法的结果(以及其他的一些特征)做个线性组合,就可以有很好的拟合能力。这是 Greg Linden在1998年提交的专利中 就提到的方法,YouTube在RecSys 2010上那篇论文也采用了这条思路。所以,Greg Linden最后写道:“What is notable here is that, despite another decade of research on recommender systems, despite all the work in the Netflix Prize, YouTube found that a variant of the old item-to-item collaborative filtering algorithm beat out all others for recommending YouTube videos. ”我想这是让很多研究人员郁闷的一个结果:10多年都白干了?
组合多个heurestic方法的结果,往往已经能够取得很好的性能了。况且Item-based方法还有很多其他的优点:
1)实现简单:复杂的模型在短平快的互联网行业很难施展手脚;
2)实时响应:Item-based方法在线运算的部分代价很低,因而可以实时响应用户的请求,比如用户新添加了几个感兴趣的商品之后,可以马上更新对用户的推荐,这对一些复杂的算法是不现实的。
3)可解释性:用户总是希望自己有最后的决定权,如果系统推荐的商品不满意,得有办法让用户改进它。采用Item-based方法,很容易让用户理解为什么推荐了某个商品,用户通过在兴趣列表里添加或删除商品,可以调整系统的推荐结果。这可能是其他方法最难做到的一点。
上述原因可能是Item-based方法被广泛使用的原因。另一方面,对于Greg Linden提到的“all the work in the Netflix Prize”,我想再次谈谈其中的矩阵分解方法。我个人认为阻碍矩阵分解方法广泛使用的原因有两个:
1)最初的最小化RMSE的矩阵分解方法不适合top-k推荐,这个我在以前的博文中谈过,目前已经有很多解决方案;
2)就像YouTube在WWW 2008的论文中提到的,Netflix只有10来万个视频,而YouTube有四千多万个视频,这对目前得矩阵分解方法是难以接受的,运算消耗太大。
我很奇怪到目前还没有任何论文尝试解决第二个问题,因为类似的问题其实在其他领域(比如分类)已经有若干年的研究了,难道不适用于矩阵分解问题?
转载请注明:jinglingshu的博客 » 几种用户相似度计算方法及其优缺点