0x00 前言
自打进了Q2之后,各种会议就不断的开始了,从4月中旬Blackhat Asia之后,紧接着就是Google Cloud Next和Google I/O,然后就是微软的Build,直到下个月初的WWDC。除了关心我手头的数码产品又有了那些新功能之外,剩下的自然就是安全领域又有哪些需要关注的点,今年毫无疑问安全的风口一定是LLM,于是就看到了各种安全大模型的使用和产品堆叠,看了这么多相关的议题之后,其实我感觉安全大模型一定是朝着两个方向去走的,中小尺寸特调模型(参数在15B以下,上下文token在8-32K长度,根据不同的场景使用不同的模型)和LLM Agent应用方向,至于怎么去构建这些能力的应用,这个就是具体问题具体分析了,虽然目前已经有一些实践,但是出于某些不可抗力的特殊原因,暂时没法分享出来。
但是在Blackhat Asia当中,我发现了一个比较感兴趣的议题。这个议题是Airbnb的安全工程师Allyn Stott演讲的,标题为《The Fault in Our Metrics: Rethinking How We Measure Detection & Response》,因为Blackhat Asia刚结束没多长时间,而且看slide上面有效的内容也不是很多,抱着试试看的态度在Youtube上搜了下,结果发现这哥们议题多投了,于是在Youtube上面找到了完整版本的视频,长度大概40多分钟(嗯,我看完了,顺便吐槽Youtube的Auto Translation是真的难用)。分析了一下之后感觉和最近几年团队在做的一些事情不谋而合,所以准备把他的这部分silde解读一下,后面图片偷懒就直接用了他的slide去做截图了。
0x01 为什么要在意检测和响应指标?
开头的时候Allyn其实直接给出了答案,因为老板们不懂入侵检测这一部分的技术细节,另外一方面,就是钱和检测工程的发展趋势。我们通过对于目前检测和响应的指标进行分析,可以进一步优化入侵检测的质量和效率。但是如果你要是使用了错误的指标去度量你的检测响应的工作呢?他引用了MIT的一篇论文阐述了你的指标是如何影响你后续的检测与响应行动,这部分行动可能是你的检测工程建设的决策,也有可能是管理层对于检测响应的战略决策,总之你后续的工作就变成了监测指标—>建设能力—>改进指标这个循环里面,久而久之,你的检测与响应能力就变成了指标驱动的工作。这个时候你的指标就变成了你的预算、你的人力资源,并且用来证明你所产生的价值,也就是前面的“钱”。
针对指标而言,其实准确去度量相关的指标是一件比较困难的事情,比如说你的能力在迭代的过程中,指标总是不断在变化的,再比如总有一些“bay guys”希望你使用一些错误的方法去度量你的指标,进而做出一些错误的决策等等。而对于安全工程师(比如他自己)来说,可能他们真的不是特别care指标(他们更关注检测和响应的技术),对他们而言,指标就是一个每次述职都要更新的东西。
0x02 五个引用错误指标的bad case
他列举了5个他职业生涯中遇到的一些比较经典的case来向大家说明使用了错误度量方式可能遇到的问题
(1)失去目标(Losing Sight of the Goal)
很多人在量化检测与响应质量的时候,一定会使用告警量作为一个比较重要的指标去进行晾晒,比如下面这样:
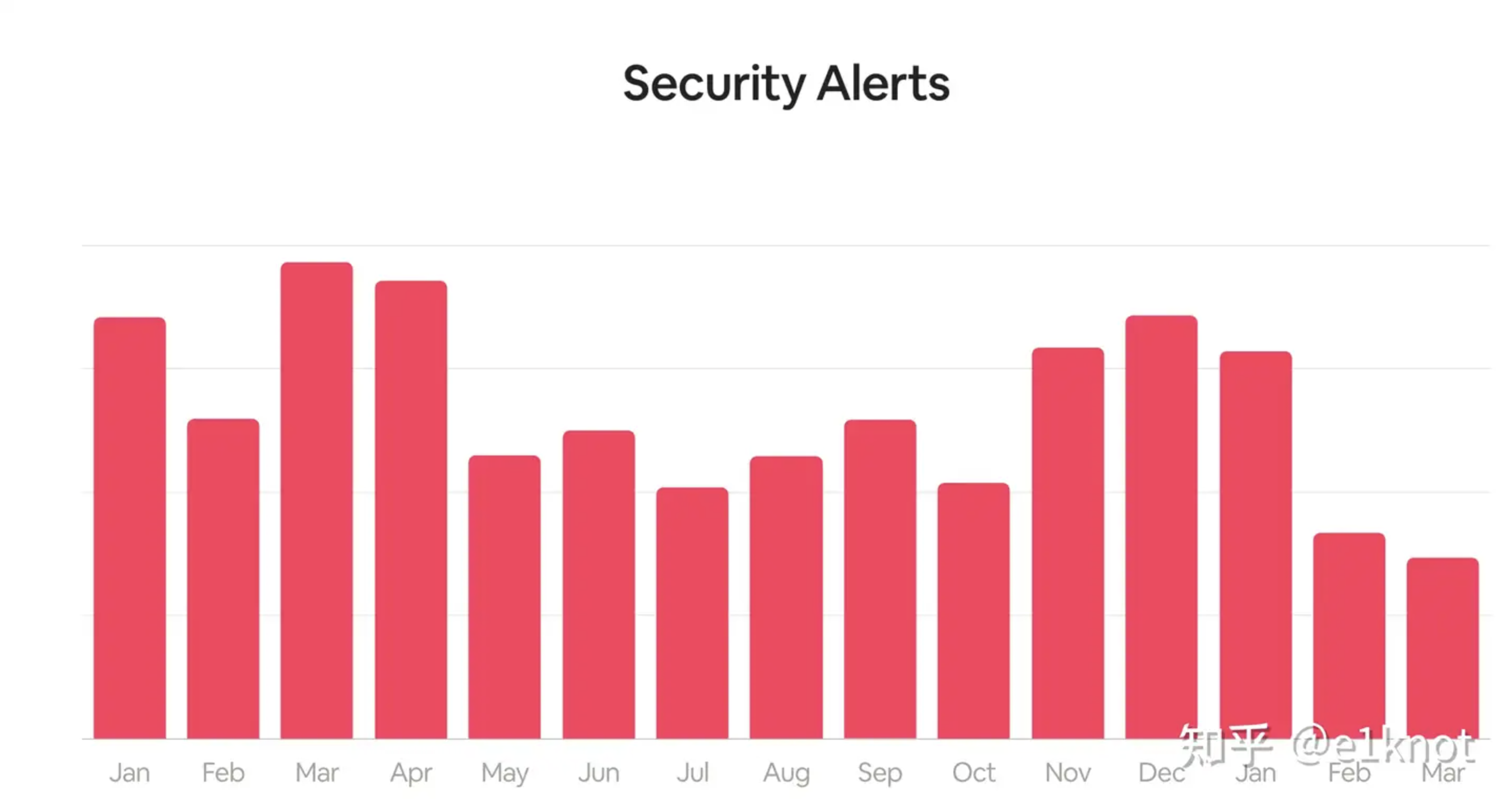
在拿到这份数据之后,管理层可能会问,为什么今年3-4月的同比数量会下去了?我们是做了哪些工作,才会让这些告警量下去了(实际情况是,1月上了很多IPS的检测规则,但是我把他们都关了,23333)。这个时候其实告警数量并不能有效的体现出检测与响应工作的有效度量,反而变成了一种负担,除了去恐吓管理层以外,并不能产生实际的作用,这个时候就会通过引入误报的概念(下文中的TP表示True Positives,表示正确的告警,FP表示False Positives,表示误报)去分解我们指标,这个时候,指标就变成了下面这个样子。
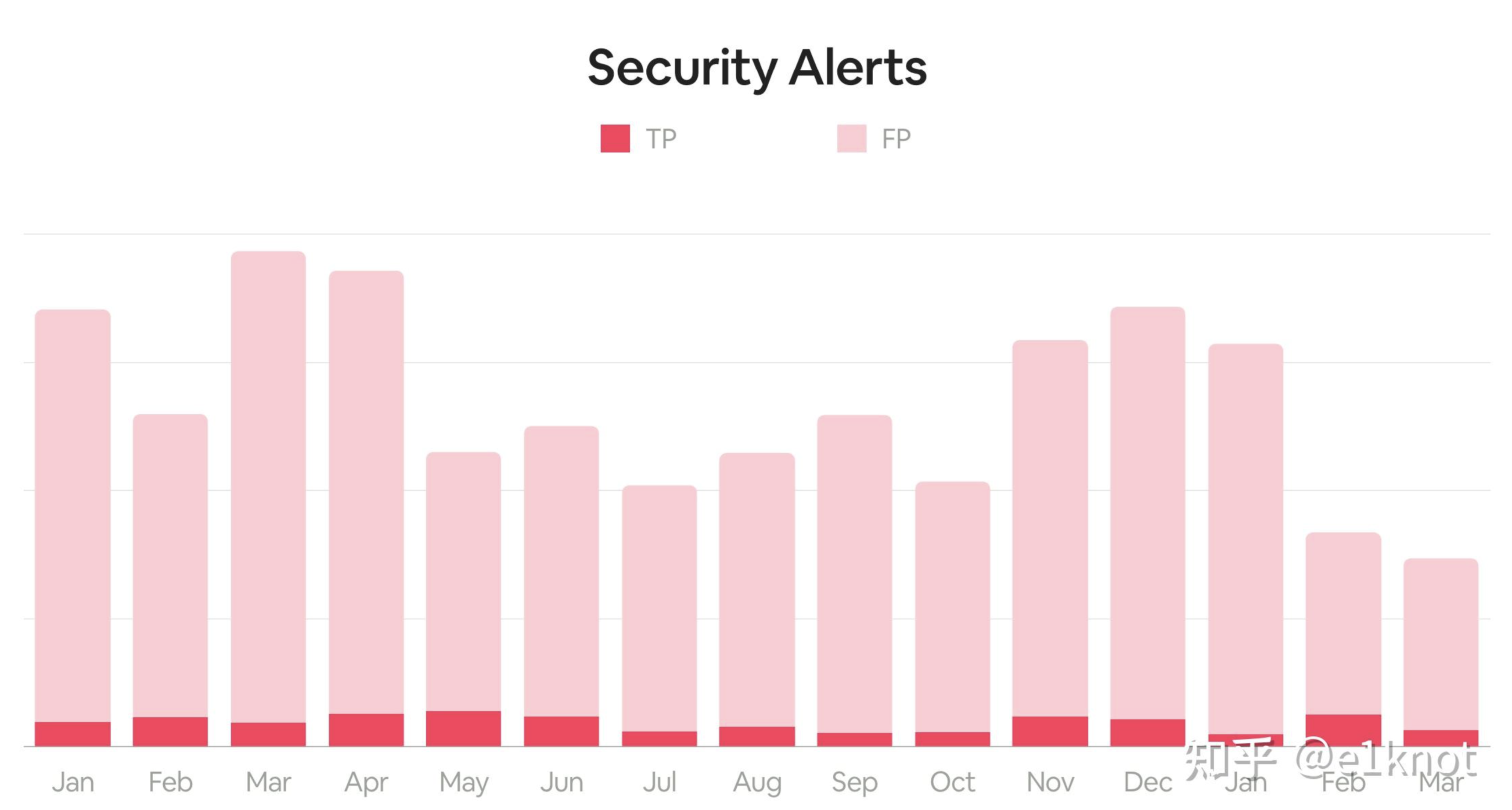
在引入了误报率这个指标之后,压力就变小了,这个时候其实站在检测与响应工程上,其实我们的主要矛盾不是每天有很多的告警量,而应该是去提升检测工程的质量,尽可能的去降低误报和运营成本。
通过上面这个例子,可以看出来,如果引入了不合理的指标,可能会导致你的检测与响应建设往不同的方向去发展,那么如何去做这一部分指标的建设呢。
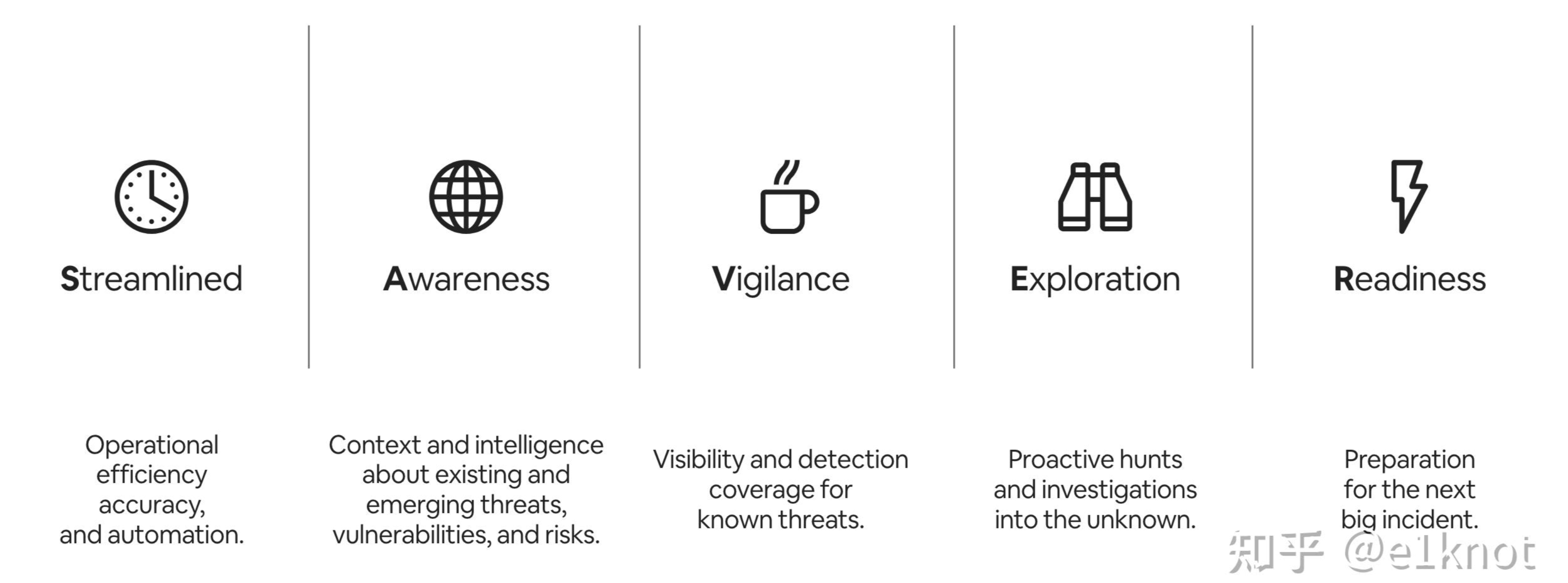
Allyn给出了一个名为SAVRE的框架,分别对应:
- 精简(Streamlined):这部分指标通常会以衡量检测效率、检测准确性、检测自动化能力做度量
- 认知迭代(Awareness):这部分主要是以获取外部威胁情报,并将其转化成为内部的威胁检测规则和防御建设的方向性指导
- 保持警惕(Vigilance):这部分主要是对已知威胁的可发现性和检测覆盖范围进行描述
- 主动探索(Exploration):这部分是通过威胁狩猎和主动发现的方式进行检测和响应
- 预案建设(Readiness):这部分是用来保证我们现在检测与响应能力是否可以应对下次比较大的安全事件
在设计指标体系的时候,可以多问自己一下:这个指标应该是在上面的类别中的哪个类别里面?这样是为了方便你去确定你的目标,并且衡量你的工作具体产出。
针对上面的数据,在引入误报率这个指标之后,我们需要确定误报率这个指标应当属于第一个Streamline类型的指标,针对当前的数据,我们可以明显发现当前监测规则是有很大的问题的,产生了大量的误报,拉低了运营的效率。但是这个指标仍然有两个问题:1. 这各指标没有告诉我们,我们把大量时间都花在了什么地方。2. 这个指标在检测团队看来,可能能干的只有两件事情,要么把规则下掉,要么就是对规则进行优化。所以这个时候我们就会引入第二个指标:处理误报所花费的时间(也就是下图中Manual的折线)。
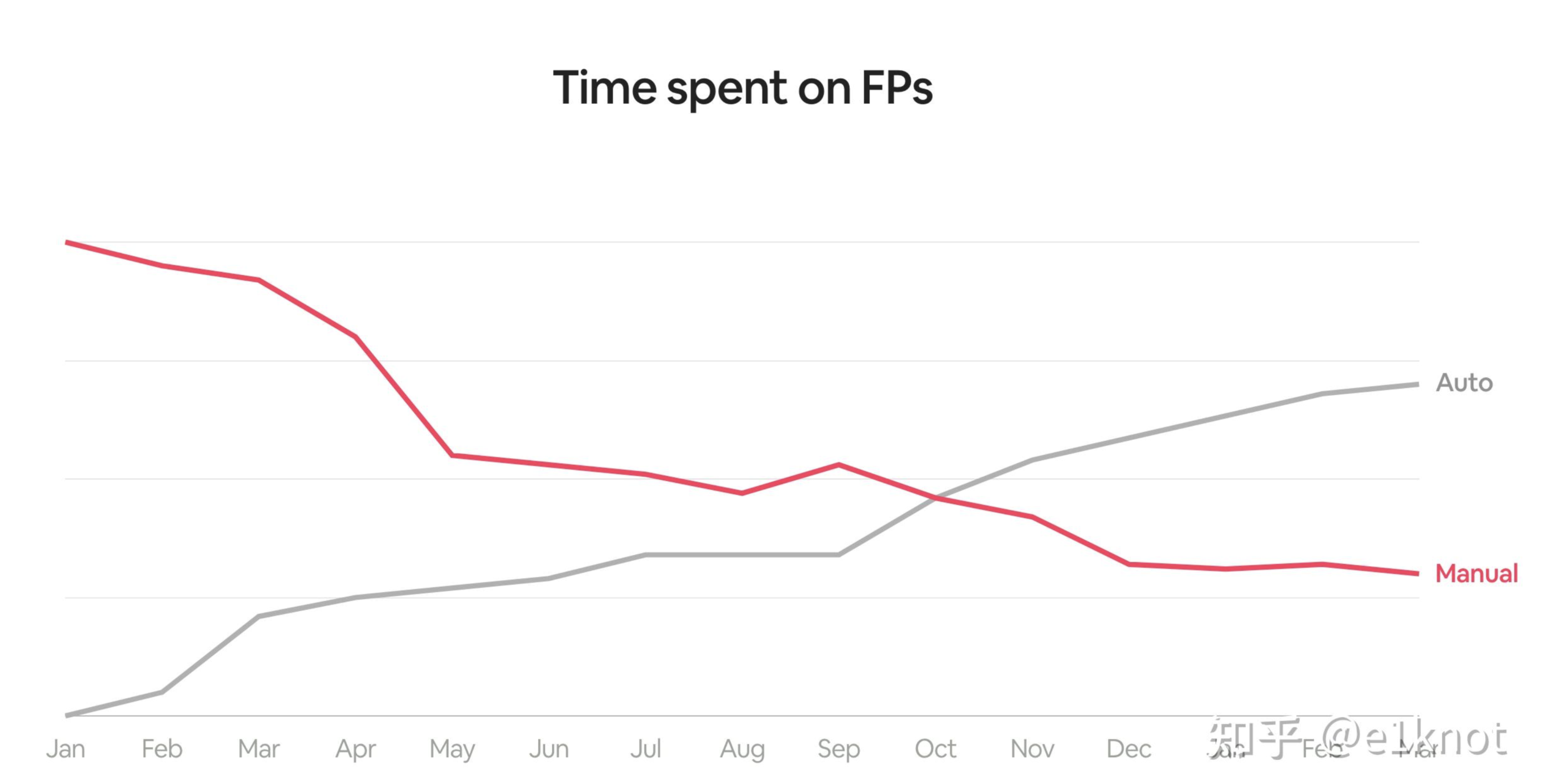
这个时候为什么不着重强调真实告警处理的时间呢,因为真实告警无论时间长短,都是有意义的,而处理误报则是在浪费时间。所以这里相比引入误报的数量而言,浪费的时间可能会更好的衡量效率。那么我们解决问题的方式就变成了如何去减少在处理误报层面浪费的时间,其实有很多手段,比如说引入自动化处理(如果你不在你的自动化Playbook里面写time.sleep(6)的话,其实自动化的时间成本应该接近于0)。这样的话,你在引入自动化之后,你可以输出你的自动化能力节省了多少人力看误报的时间。其实绝大多数的时候,我们没有太大的动力去做一些自动化的操作,因为自动化的工作很有可能不会反映在一天的告警处理量上面(所谓短期没有产出),但是在把这个指标引入到核心指标里面的时候,大家就都有动力了(比如优化规则),结果就是上图中灰色的Auto的线。
(2)度量一些不可能改变的数据(Using Quantities That Lack Controls)
在这个case当中,我们会引入MTTR(Mean Time to Recover)业务恢复时间作为case。以下图为例:
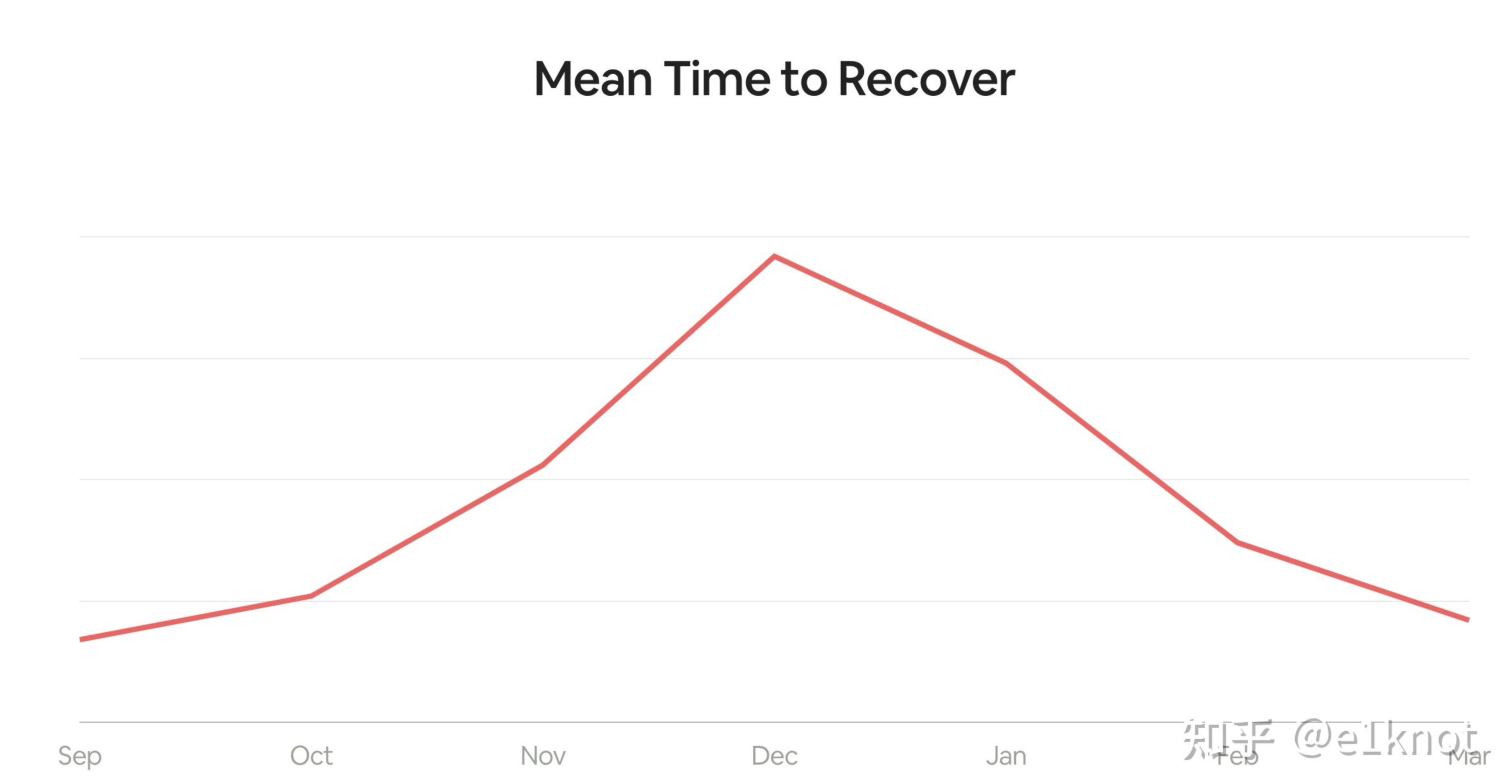
如果只看数据,我们会发现MTTR在12月的时候上涨了接近300%,然后可能觉得检测响应团队努力工作了一段时间之后,MTTR又恢复到了原来的水平。我们在实际的检测响应运行过程中,可能非常重视各种时间指标,比如说MTTD、MTTA、MTTR等,不能说时间这件事儿不重要,只是说我们不能以时间为唯一的衡量标准,忽略了应急响应的质量和有效性。
其实对于MTTR指标来讲,其实在事件响应的过程当中会发生很多不可预知的情况,随着你分析的越深入,可能发现的问题也就越多,甚至会左右响应的方向和思路,对于安全事件这种情况,其实MTTR是完全不受控制的,所以这个时候MTTR的数据是完全没有办法去支撑你做任何决策的,这个时候其实你可以放弃以MTTR作为唯一输入的指标,可以换一个思路。
如果我们不希望别人看到一份数据之后无法回答该做什么,那么就不要让这份数据在报表中展示出来,所以我们会把指标分解成以下几个数据进行展示。比如下面这样
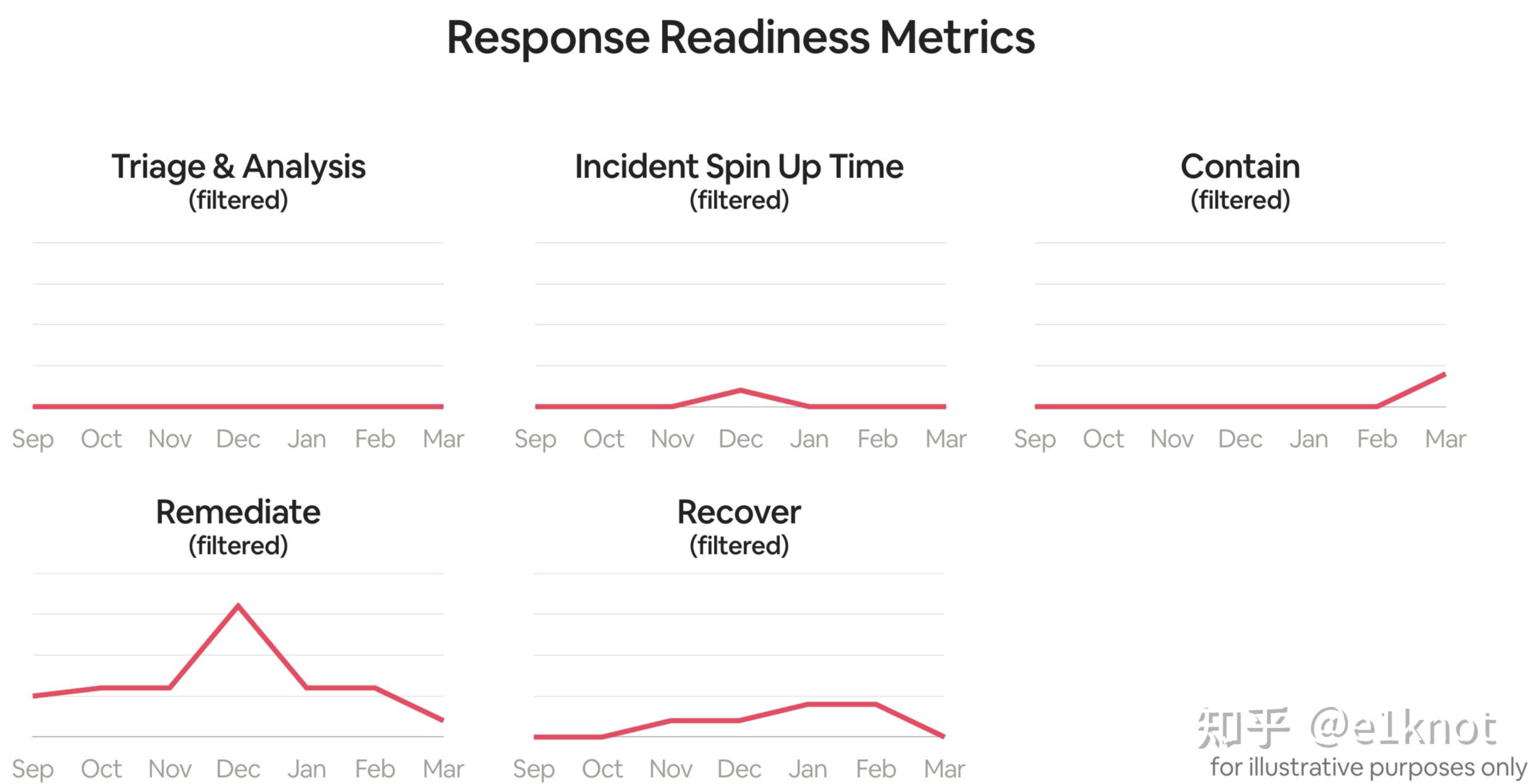
当你把一些不可控的数据过滤掉之后(比如说一些Playbook的执行时间这种完全没意义的数据),剩下的数据都是一些可控的数据了,这样的话就可以很直观地知道我们该做哪些事情,因为安全事件处置过程中的复杂度(比如说卷入了更多的团队、需要协调更多的资源)不同,所以我们只需要去观察指标的变化,就可以去你能控制的那些地方可以做优化。
(3)认为间接指标没有用(Thinking Proxy Metrics Are Bad)
在很早之前,入侵检测团队基于MITRE ATT&CK的覆盖度做了一份数据,用来描述目前哪些TTPs存在一些盲区和可以覆盖的地方。因为很多安全产品和公司都这么做了。然后,因为在追求足够高的覆盖度,所以我们的告警数量会变得异常的多,多到已经处理不过来了。所以我们后面对所有的ATT&CK TTPs做了测试用例,但是实际上,我们发现并不用对所有的TTPs做测试,因为利用方式和可变性实在是太多了。虽然说花了好几年时间完成了这件事儿,但是,我们似乎失去了目标,因为我们一开始只是想知道,我们还应该检测哪些东西。很显然,MITRE ATT&CK并不能回答这个问题。
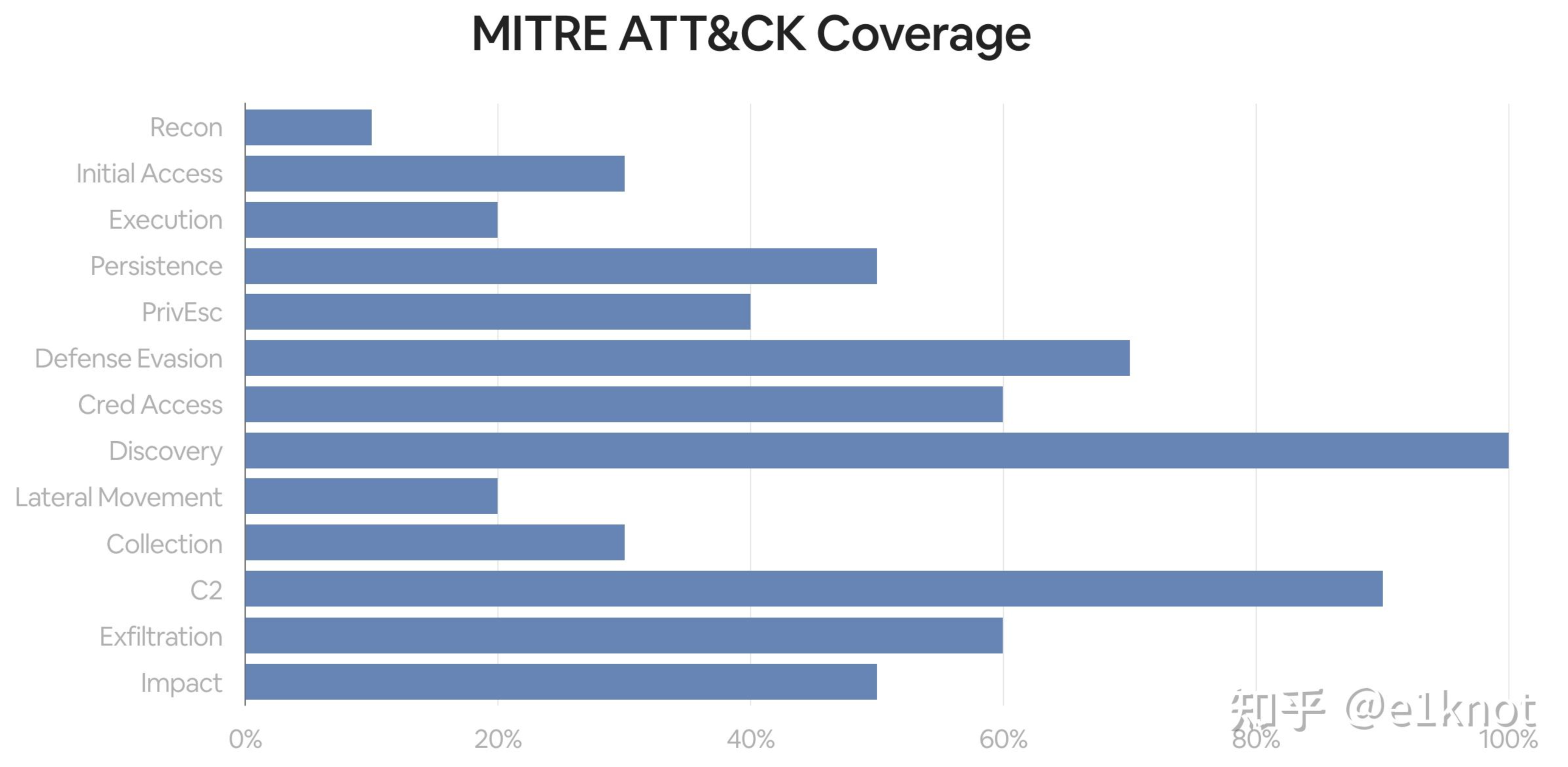
这个时候我们需要去梳理一下我们到底面临何种威胁,尤其是针对我们业务可以产生实际危害的威胁(比如说数据泄露),其实可以通过使用外部威胁情报、内部的事件数据的趋势以及企业实际的安全风险进行梳理,梳理出top5的风险即可,然后做对应的检测工程即可。

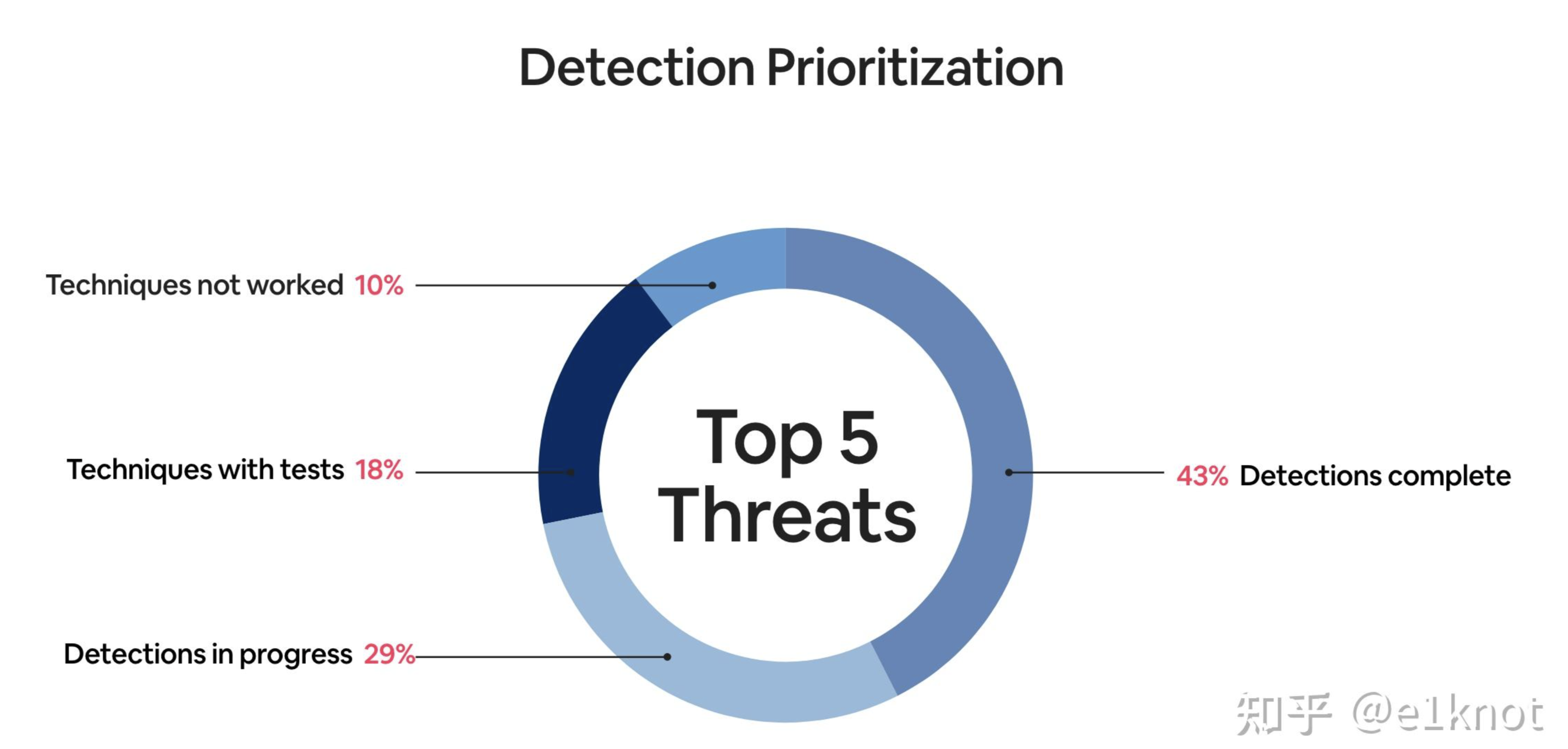
这个时候其实我们并不需要所谓的MITRE ATT&CK,相反我们需要一个检测工程建设的优先级考虑,实际上我们需要针对top5的风险做一些告警质量的复盘,做一些测试用例(Purple test),然后找到哪些技战术无法检测,然后进行检测规则的迭代即可。这个时候实际上你得到了一个更好的TTPs图,并且没有任何告警疲劳。
(4)对合适的人说合适的指标(Not Adjusting to the Altitude)
这一部分主要涉及到“向上管理”,因为针对做检测响应的工程师和管理层而言,他们或多或少都会关注一些指标,但是他们的指标可能完全不是一回事儿,对于做检测工程的工程师而言,他们可能觉得前面提到的自动化处置率和检测覆盖度这种指标是非常有效的,但是安全管理层可能更关心所谓核心指标(North Star),比如说MTTR、MTTD这种比较模糊的指标。比如说你拿着MITRE ATT&CK的覆盖热力图直接递交给管理层,他们一定是一头雾水,这样会让你的工作产出变得很糟糕。
所以这个时候我们需要对我们的指标进行一个梳理,越靠上的指标可能跟应急响应本身工作关系不大,但是业务对这方面的感知是非常明显的。如果我们要是把这些指标整理成一个金字塔的样式的话,大概会跟下面的金字塔一样。

在最上面的是对业务影响较大的指标(MTTD关乎到我们大概多久可以发现威胁,MTTR表示我们需要花多长时间可以让业务恢复到原来的样子);再往下走就是一些核心的性能指标,比如说检测规则的覆盖度和响应的效率,用来衡量你是否检测到对业务的最大的威胁,并且是否有足够效率的Playbook来高效的完成响应和处置;最下面一层是一些效能指标,这些指标用来衡量我们在成本一定的情况下可以做的怎么样,比如说工具执行需要花费多长时间、我们搜索日志大概需要多长时间。
将各种指标按照金字塔的方式整理好并且有选择的回报,可以让你的汇报对象更容易理解你的工作效果,从而更好地评价我们的方向是否对了。
(5)学会正确的问问题,不是问为什么而是讨论怎么做(Asking “Why?” instead of “How?”)
正常的情况下,我们会问Why多一点,比如说:
- 我们为什么没有更早的检测到恶意软件的活动?
- 为什么我没有在灰度环境下拿到对应的防火墙数据?
但是在正常的情况下,我们其实更应该关注How。举个例子,比如说:
- 我们该如何去更早的检测到恶意软件的活动?
- 我们该如何去建立一套现代化的检测响应体系?我们该如何去设计它?
简单的问题背后往往不是一个简单的答案。我们该如何描述我们的能力现状以及我们要做哪些工作才能让我们的能力达到对应的水平。这个时候我们就需要引入成熟度模型的概念,很多人第一次接触成熟度模型(Maturity Model)是在解除威胁狩猎这一概念的时候,通过引入成熟度这一指标,非常有助于让我们了解我们威胁狩猎的能力如何,能让我们更清楚的知道我们接下来该做什么可以让我们的成熟度更上一层楼。
拆解一下成熟度指标,其实就是对于三个问题的答案:
- 我们现在是一个什么样的能力和体系?
- 我们需要的是一个什么样的能力和体系?
- 我们需要做哪些事情才能让我们达到我们想要的能力和体系?

我们以威胁检测与响应成熟度模型(TDR Maturity Model,TDR是Threat Detect & Response的缩写)为例子:

首先是可观测性(看得到),这个是我们TDR能力的基础,它会包含一系列工具和日志方便我们去了解用户的行为并且对这些数据进行丰富,方便我们对有问题的数据上下文进行快速的搜索。第二个支柱是主动威胁检测,依据高质量的威胁情报以及高校的检测能力,我们能够迅速地发现针对业务的威胁。第三部分是快速响应,主要是依赖我们的高质量的Playbook和自动化处置能力,以便我们在发现威胁之后快速清除威胁并恢复业务,让整个响应团队的工作重心从止损换成调查和分析。我们对以上的工作进行拆分,拆分成14个能力用来描述我们现在的能力成熟度。
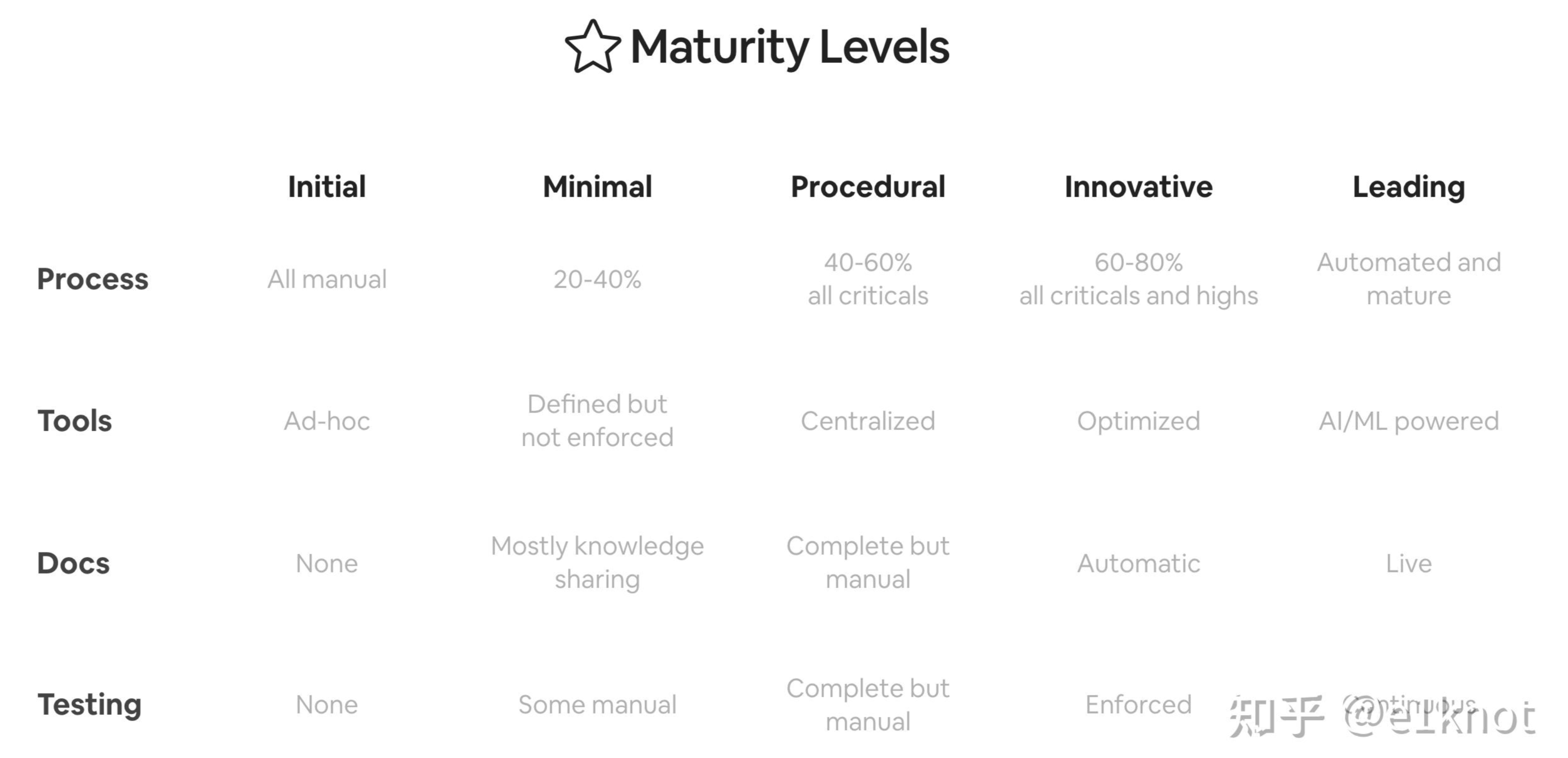
首先要客观的回答一个问题,我们现在的每一个能力是一个什么样的水平。每一个项目你关心的点是这项能力的流程、工具、文档和拨测是否都已经准备完全,同时对齐整个行业的标准划分成5个level,分别对应起步、小规模、流程驱动、创新和业界领跑五个不同的成熟区间。比如说下面这样:
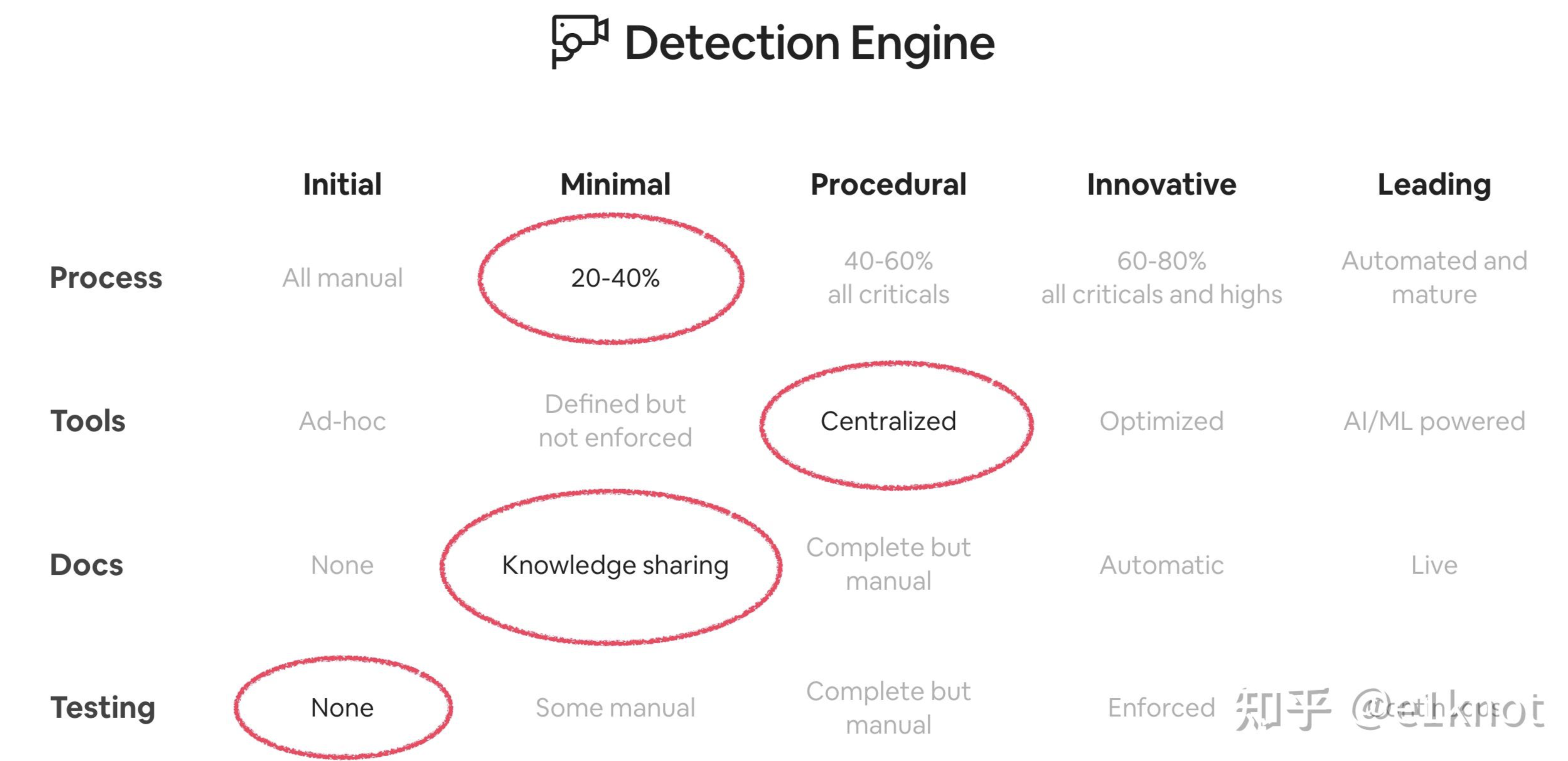
再经过不断对齐之后,我们接下来就可以根据成熟度和目标进行进一步的量化:
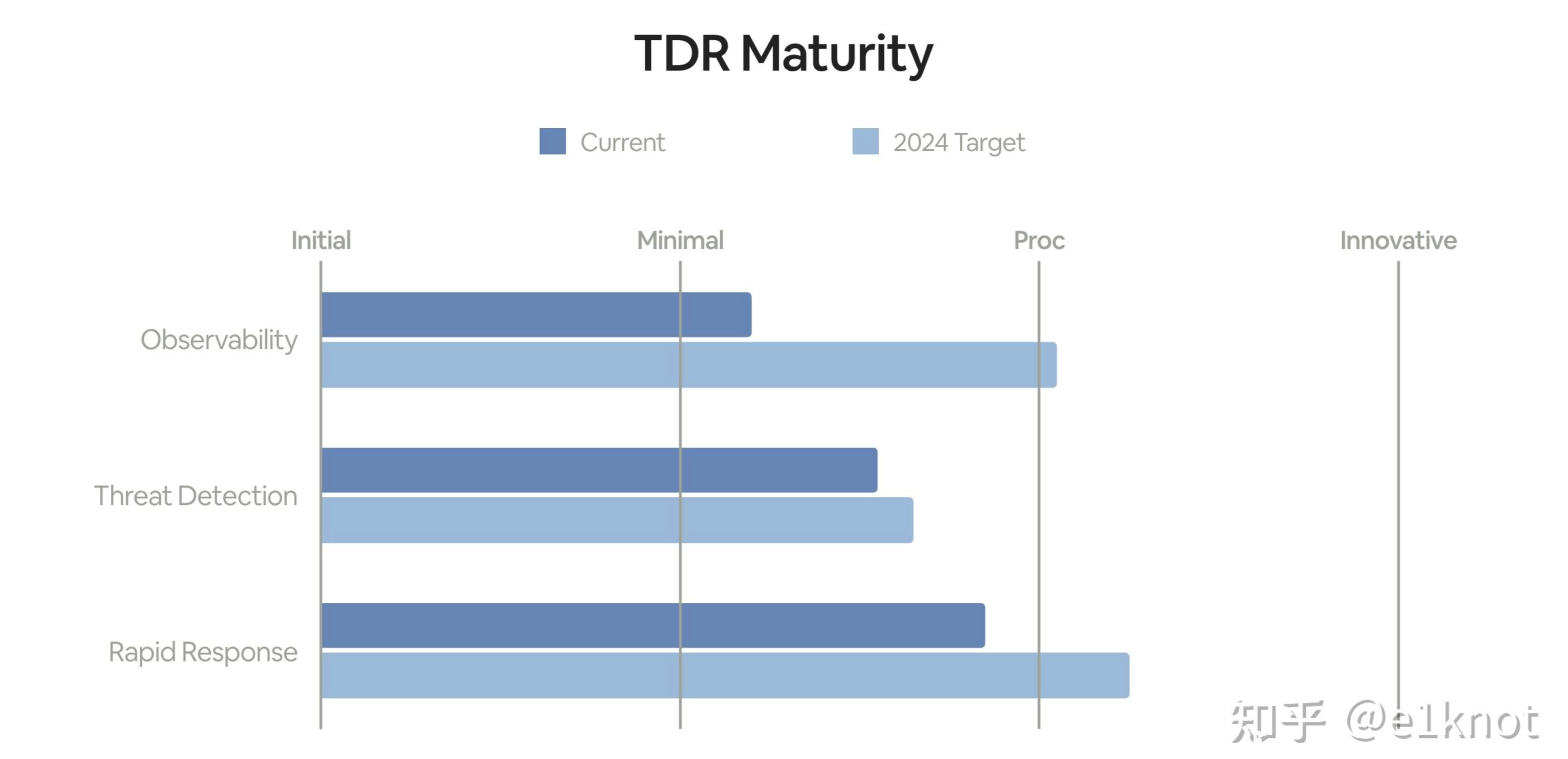
这样的话,你在年初做规划的时候,就可以把一些关键的可以影响到这些能力成熟度的项目进行立项,并且持续观察项目的成熟度。这样的话,对上你可以很清楚的阐述我们要干的事情是如何影响到业务的,对下你可以让工程师更好的了解自己的工作所产生的价值。
接下来的话,我们就需要通过一些指标去衡量我们是不是在做正确的事,结果是什么,能不能做的更好,以及我们是不是需要去调整我们的策略。这个时候,我们又需要引入上面的SAVER框架并进行一定的扩展,来进行指标的确定。并继续去回答类似于上面的问题:这些指标可以回答哪些问题,我们希望实现怎样的效果,这类指标的提升将如何影响我们核心指标。

当在你引入新的指标的时候,团队成员不可避免的会在分析指标上面花费不少的时间,所以我们思考这些指标的引入可能会对现有的能力产生那些风险。可能这些指标不会变差,但是你需要去考虑那些与之配套的指标,因为你作为一个检测团队的成员,你自己也是需要被衡量的。
指标也需要根据实际情况需要进行更换,因为你在不同阶段的建设工作中,可能主要矛盾变了,比如说在优化误报率这个指标上面,我们前期已经建设了足够多的自动处理能力,所以我们可能后面需要把精力转换到其他的主要矛盾上,这个时候误报率就变成了一个我们不需要关注的指标,这样可以让我们的时间更聚焦在处理主要矛盾上。
最后,我们需要考虑在构建指标的时候,我们需要哪些数据,以及构建这些指标的成本和效果是否能达到我们的预期。
0x03 summary
虽然在指标体系构建这一层面上确实有很大的工作难度,并且管理层其实并不喜欢给他们惊喜(这话我怎么感觉谁跟我说过),可能他们更喜欢你在之前汇报的数据上做一些更新然后告知他们。
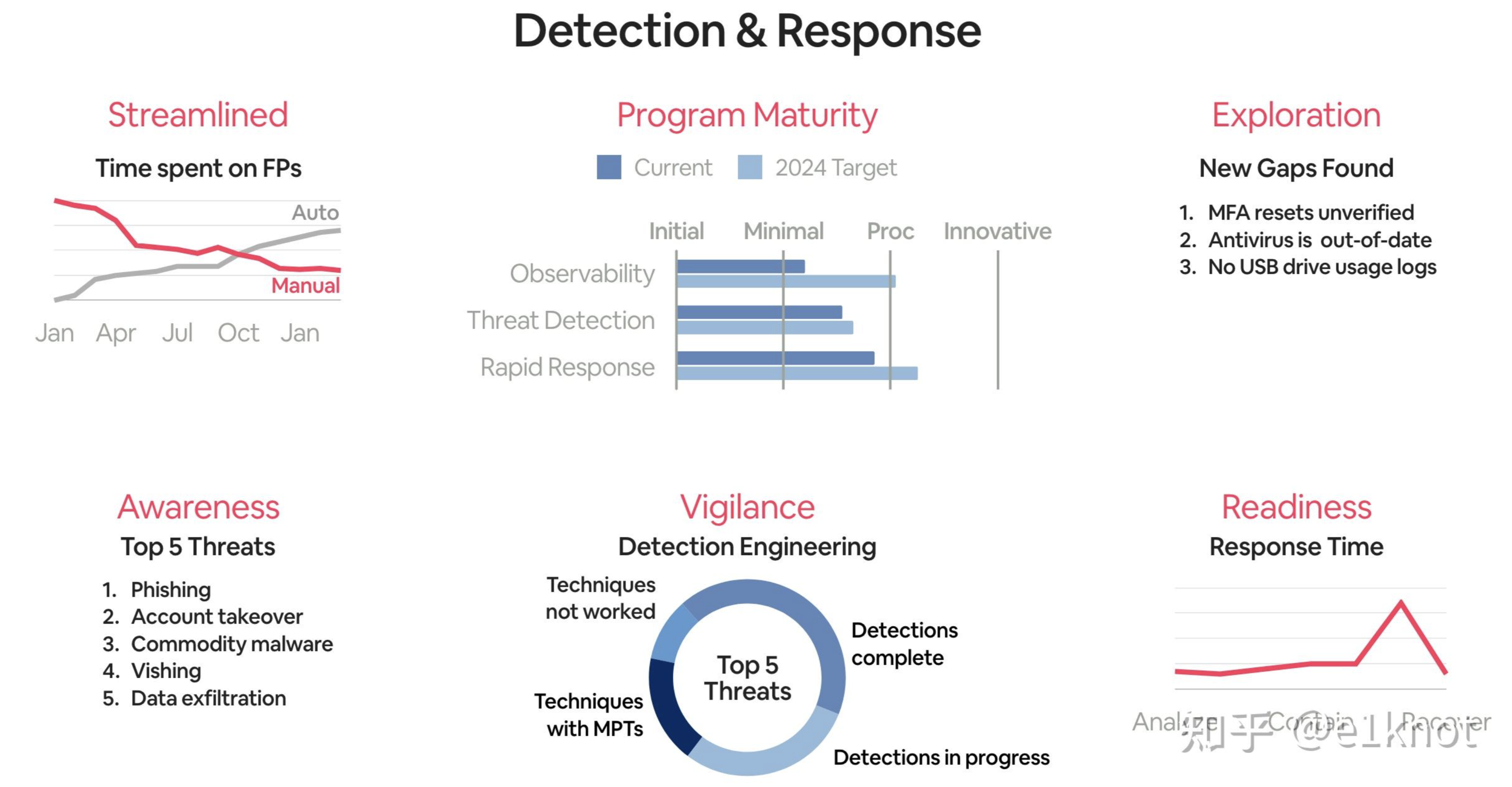
对于一些人来说,可能需要花费很长的时间才能接受这些东西,所以我们需要尽可能的打破舒适区,尽可能的解决掉那些不合理的指标,让我们的建设目标变得清晰。就像下面这样:
0x04 REFs
视频链接:https://youtu.be/IPYti3PoooE?si=CRmzBNXBSd54fTFb
Slides:https://i.blackhat.com/Asia-24/
Asia-24-Stott-The-Fault-in-Our-Metrics
转自:https://zhuanlan.zhihu.com/p/700161786
转载请注明:jinglingshu的博客 » 如何有效的量化入侵检测与响应能力