狩猎相似的恶意样本始终都是安全研究人员孜孜不倦追求的目标。通过已知的样本查找相似的样本,可以应用在家族归类、攻击归因等多个场景中,帮助分析人员更高效地挖掘样本与数据的最大价值。各个厂商也都介绍过一些使用案例,包括在跟踪 APT 样本上亦有使用。
本文各有详略地介绍了二十余种哈希,虽然想要尽可能地覆盖更多信息但肯定仍有不足,感兴趣的同学可以进一步拓展阅读提供的相关链接。
一般哈希
MD5、SHA-1、SHA-2(SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256)等这些常见的哈希函数在业界有着广泛的应用,例如 siphash 被应用在 Python、Rust、Perl 等编程语言中。各方也都在努力设计更好的哈希函数,例如 Austin Appleby 提出的 murmur 就被 memcached 用作默认的哈希函数。
NIST 提出了“密码学算法验证计划”(CAVP)来对密码学算法进行科学的评估测试。社区也在为这些哈希函数构建评估和测试,其中以 SMhasher 为典型,测试了百余种哈希函数:

通常来说,对哈希函数的评估主要集中在速度上,“安全性”并不是业界着重关注的要点。只是在算法设计时,一般必须关注“雪崩效应”,即输入上极其微小的改变也会导致输出出现极大的改变;和“抗碰撞”,即两个不同的输入产生相同的输出。
尽管业界早就提出哈希函数存在碰撞的问题,但直到 2004 年,王小云研究团队才首次对外展示了 MD5 的碰撞实例。转年,王小云与姚期智合作再次碰撞了 SHA-1 算法。紧接着业界讨论制定出了新的哈希函数标准 SHA-3,但由于尚未研究出对 SHA-2 算法的高效碰撞方法也未被推动大面积使用。
在能够找到碰撞样本的情况下,已经不推荐使用 MD5 和 SHA-1 算法来使用,在样本狩猎与样本检索的场景中也不推荐使用。而且此类哈希算法的“雪崩特性”也导致在痛苦金字塔中,哈希是最容易被改变的。
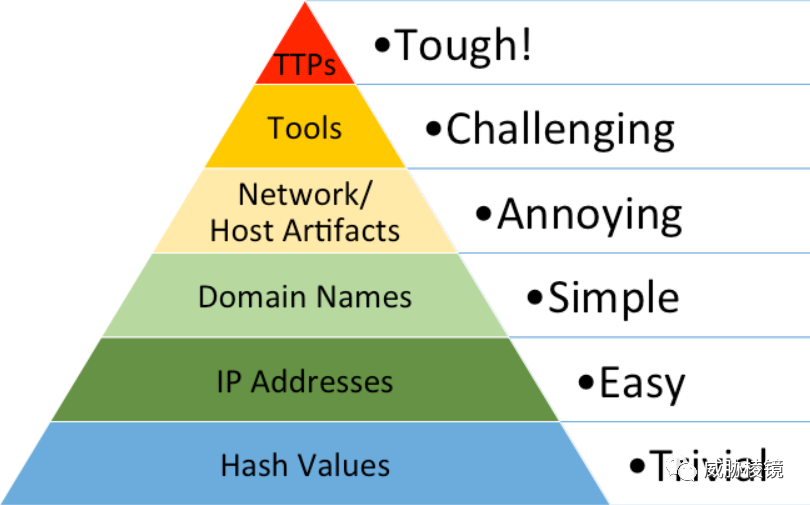
一致性哈希等特定类型的哈希函数都有着特殊的用处,不过此类哈希并不是本文的重点,不加赘述。
spamsum
简介
2002 年由 Andrew Tridgell(Samba 和 rsync 的作者)提出,基于局部敏感哈希算法识别与已知垃圾邮件相似的未知垃圾邮件。
原理
使用 spamsum 算法主要分为两步:第一步生成小于 64 个字符的 ASCII 字符串作为哈希,第二步与已有哈希计算匹配程度。
每个被切分的文件块都会被计算成一个字符,哈希太长或者太短都不合适。一旦已经找到 63 个文件块,直至文件结尾都会被视为最后一个文件块。而如果文件块不超过 32 个,spamsum 会减小每个文件块的长度,获得更长的哈希值。
spamsum 算法其核心类似与 rsync 算法的滚动哈希,同时基于编辑距离衡量哈希结果的差异性。但 spamsum 无法保证较低的碰撞率,任何两个不同的块都有 1/64 的概率计算出相同的哈希值。
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.samba.org/ftp</span><span class="code-snippet__regexp">/unpacked/junkcode</span><span class="code-snippet__regexp">/spamsum/</span>README</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/github.com/freakboy</span>3742/pyspamsum</span></code>
Nilsimsa
简介
Nilsimsa 也是一个针对垃圾邮件的局部敏感哈希算法,0 为不相似,128 为非常相似。
原理
使用固定大小的滑动窗口(5 字节),组合产生输入字符可能的三元组。将三元组映射到 256 位的数组,再使用哈希函数对数组进行处理,处理得到最终的 32 字节哈希值。由于该哈希函数使用的相对较少,不过多介绍。
缺点与对抗
- 与后续的 TLSH、SSDEEP 和 SDHash 相比,nilsimsa 的误报率高得多
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/github.com/diffeo</span><span class="code-snippet__regexp">/py-nilsimsa/</span></span></code>
SSDEEP
简介
2006 年提出,基于 SpamSum 算法的模糊哈希算法,最新版本是 2017 年 11 月发布的 2.14.1。ssdeep 被业界广泛使用,例如 VirusTotal,其计算速度大概是后起之秀 TLSH 初版的两倍。
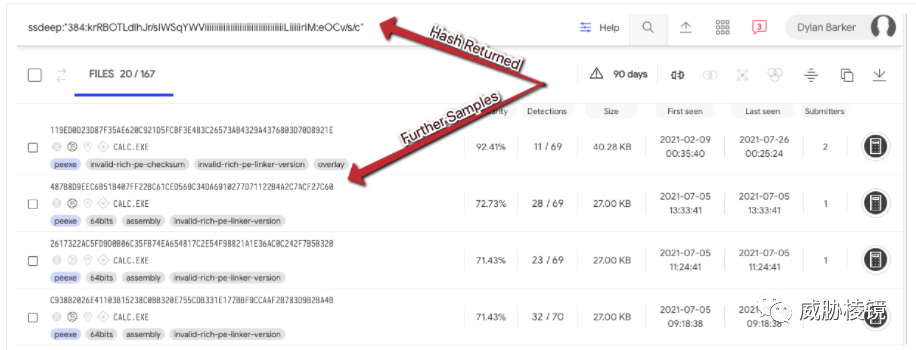
原理
其格式为:chunksize:chunk:double_chunk,具体如下所示:
- chunksize 为切分的块大小
- chunk 的每个字符都代表原始文件 chunksize 长度的内容
- double_chunk 的每个字符代表 chunksize*2 长度的内容
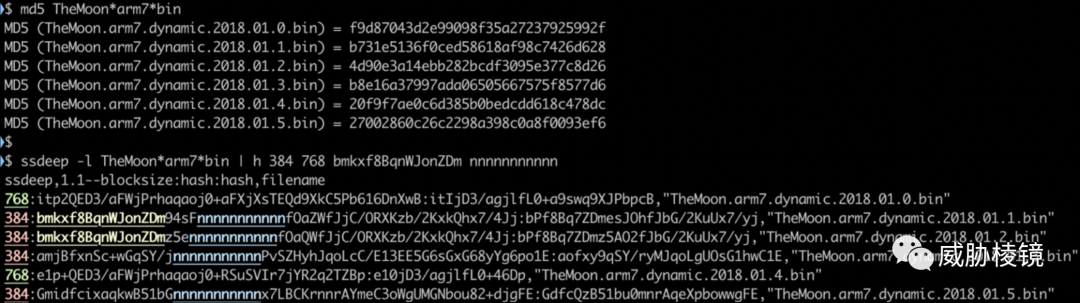
使用 6 个 TheMoon 的样本,尽管每个样本的 MD5 都不相同,但从 ssdeep 却可以看出有相似之处。
当然,如果样本量非常大,ssdeep 自身提供的比较方法就难以应对了。Brian Wallace 在 Virus Bulletin 分享过应对大规模样本场景下如何高性能使用 ssdeep,主要通过减少需要比较的哈希数量来提高性能,其中主要包括:
- 只比较 CHUNKSIZE 相等、CHUNKSIZE*2 或 CHUNKSIZE/2 的 ssdeep
- 只比较 chunk 或 double_chunk 中有七个字符串相同的 ssdeep
缺点与对抗
- 可以添加一个 section 修改 ssdeep 的哈希
- 容易受到主动攻击
参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//www.sciencedirect.com/science/article/pii/S1742287606000764</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/ssdeep-project/ssdeep</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//nikhilh20.medium.com/fuzzy-hashing-ssdeep-3cade6931b72</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//www.virusbulletin.com/virusbulletin/2015/11/optimizing-ssdeep-use-scale</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//www.intezer.com/blog/malware-analysis/intezer-community-tip-ssdeep-comparisons-with-elasticsearch/</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/a4lg/ffuzzypp</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/a4lg/fast-ssdeep-clus</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/bwall/ssdc</span></span></code><code><span class="code-snippet_outer">《Security aspects <span class="code-snippet__keyword">of</span> piecewise hashing <span class="code-snippet__keyword">in</span> computer forensics》</span></code>
imphash
简介
FireEye 在 2013 年首次提出 PE 文件导入表可用于跟踪同一个攻击组织的恶意样本,而 Mandiant 在 2014 年应用于在 356 个样本中取得了不错的效果而被广为人知。
注:FireEye 在 2021 年 6 月已经已经将 FireEye 出售给了 Symphony 组织的财团,只保留了 Mandiant Solutions 部分,所以表述尽量做了区分。
原理
源码的函数顺序以及源文件的顺序的改变都会导致编译时生成不同的导入表,也就有不同的导入表哈希。反过来说,如果两个文件的导入表哈希相同,即导入表相同,意味着文件是使用相同的源码通过相同的方式编译而来的。
imphash 的计算方式是将 PE 文件导入表中的函数名与 DLL 名连起来,全部小写化后计算 MD5。
使用 LokiBot 的样本作为示例,样本通过 KERNEL32.DLL 导入 GetTempPathA()、GetFileSize()、GetModuleFileNameA() 和其他函数。
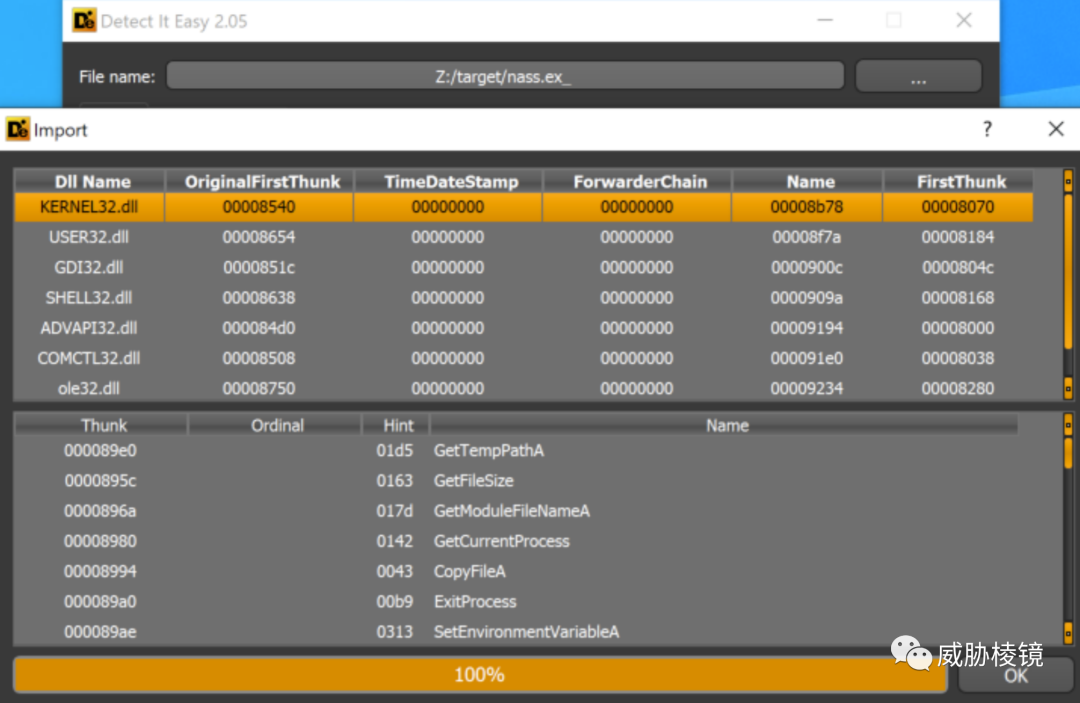
这样可以将使用相同导入表的样本都找出来。
缺点与对抗
- 如果加壳程序在运行时重建原始导入表,这样就会因为使用相同的加壳程序而产生误报
- 攻击者可以将整个恶意软件模块化,按需加载到内存中执行
- 攻击者可以将导入表中的大部分都动态加载,保持导入表在最小
- 攻击者可以构造特定的导入表来诱导错误归因
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.mandiant.com/media</span><span class="code-snippet__regexp">/10316/download</span></span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.mandiant.com/resources</span><span class="code-snippet__regexp">/tracking-malware-import-hashing</span></span></code>
impfuzzy
简介
JPCERT/CC 在 2016 年发现一旦添加了新函数,生成的导入表哈希就会完全不一样,但这样不同导入表哈希的两个样本可能仍然有很高的相似度。故而 JPCERT/CC 开发了 pyimpfuzzy:
原理
由于 imphash 使用 MD5 就要求导入表完全一致,但 impfuzzy 使用 ssdeep 作为哈希函数可以得到更好的效果。与 imphash 的区别只是使用 ssdeep 替换 MD5 作为哈希函数,其他都与 imphash 保持一致。使用 Dyre 银行木马为例,如下所示:

使用多个家族的样本进行测试,普遍来看 impfuzzy 的效果要好于 imphash:
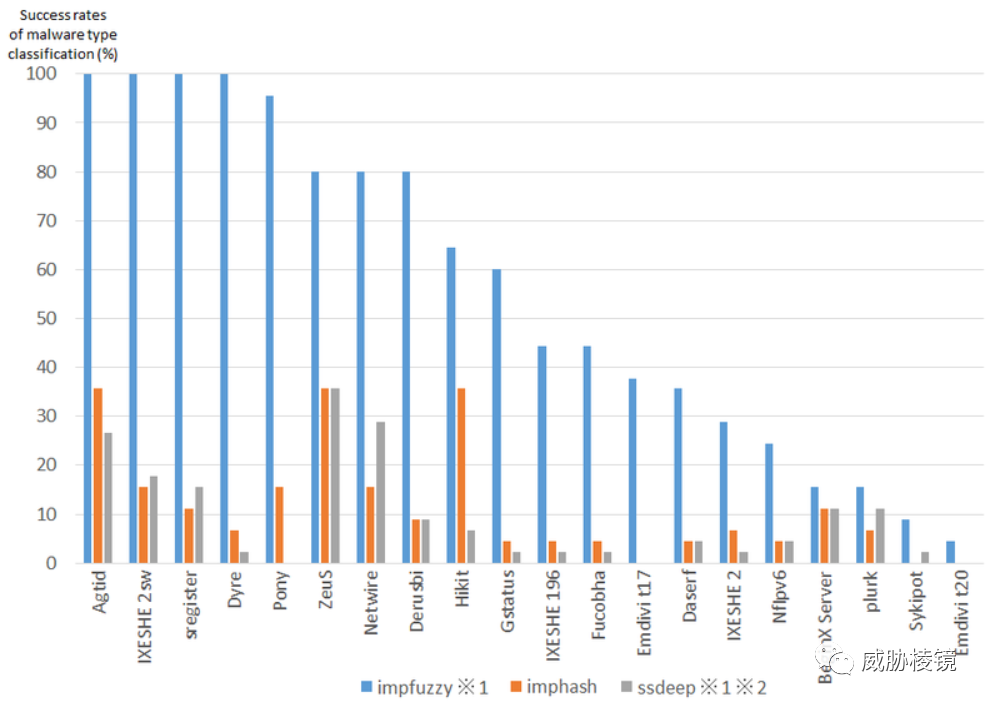
缺点与对抗
- 对使用构建工具的恶意软件(如 Pony、Zeus 等)比较有效,但变种很多的效果不好
- 有些恶意软件导入表很短,使用的 Windows API 太少的情况下基本无效
- .NET 文件与直接执行 Windows API 的文件调用机制不同
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/github.com/</span>JPCERTCC/impfuzzy/</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/blogs.jpcert.or.jp/en</span><span class="code-snippet__regexp">/2016/</span><span class="code-snippet__number">05</span>/classifying-mal-a988.html</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/blogs.jpcert.or.jp/en</span><span class="code-snippet__regexp">/2017/</span><span class="code-snippet__number">03</span>/malware-clustering-using-impfuzzy-<span class="code-snippet__keyword">and</span>-network-analysis---impfuzzy-<span class="code-snippet__keyword">for</span>-neo4j-.html</span></code>
richhash
介绍
Rich Header 是微软并未公开的信息头,没有任何描述该结构的官方文档。从 Visual Studio 6(1998)甚至更早(一说是 Visual Studio 97 SP3)就开始包含 Rich Header。根据 ESET 的数据,在一百万个恶意 PE 文件中,73.2% 的样本都包含 Rich Header。
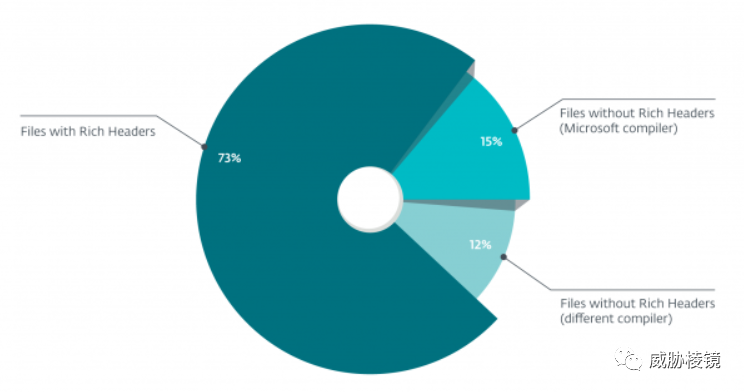
其余不包含的样本,很多都是由其他编译器(Turbo C++、MinGW GCC、Clang 等)或是使用其他语言(Delphi、Go 等)生成的。如果去掉这些样本,包含 Rich Header 的比例将上升到 83.3%。根据分析,缺少 Rich Header 的情况基本都是恶意软件开发者自己删除或者使用自定义壳导致没有 Rich Header。
原理
Rich Header 是使用 Microsoft Visual Studio(LINK.EXE)编译链接的可执行文件的 PE 头的一部分(Rich Header),位于 MZ DOS Header 之后。
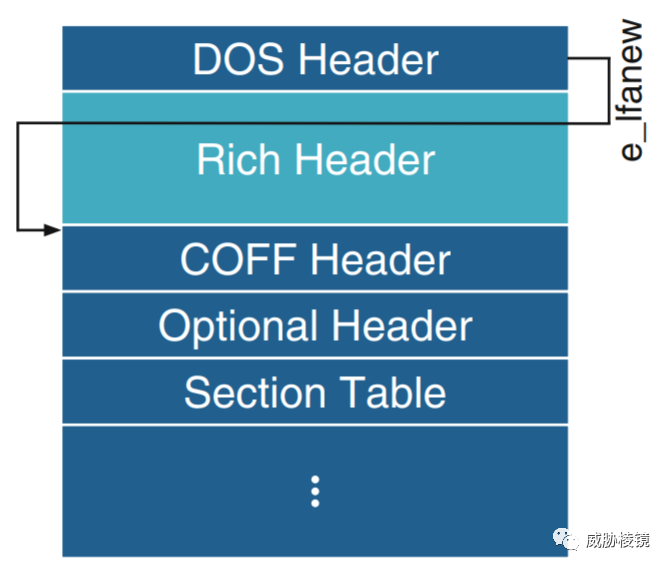
Rich Header 以 DanS 开始,以 Rich 结束,随后是校验和(并且使用校验和作为异或加密的密钥)。
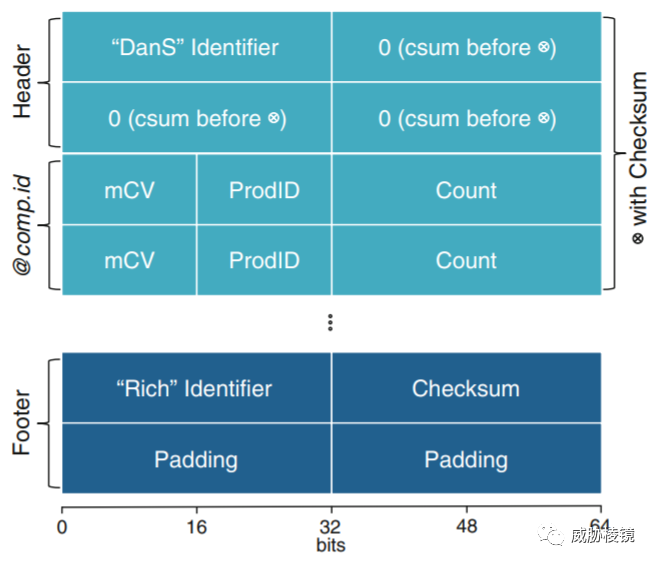
Rich Header 中包含构建环境信息,基本结构如下所示:
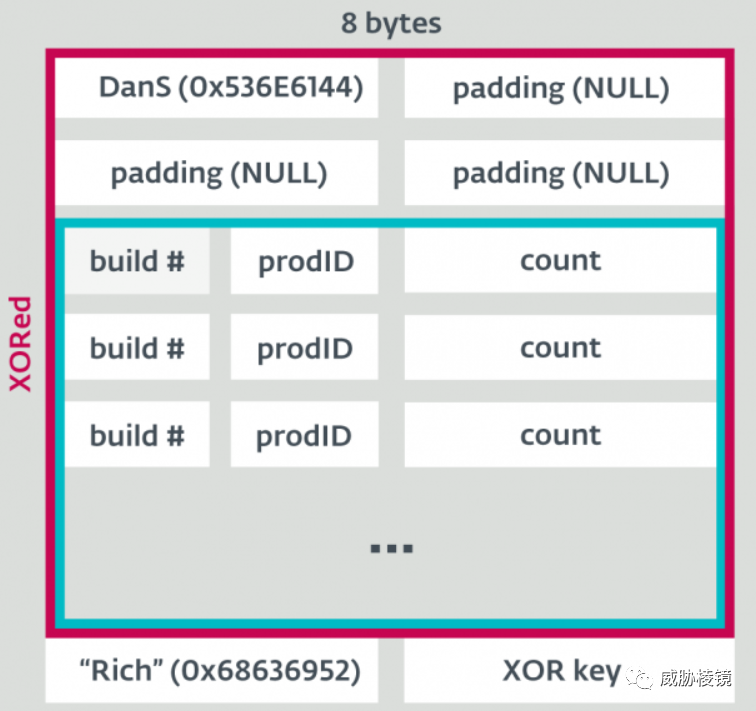
例如攻击平昌冬奥会的 OlympicDestroyer 使用的 wiper 组件(3c0d740347b0362331c882c2dee96dbf)的 Rich Header 为:
<code><span class="code-snippet_outer"> Raw <span class="code-snippet__keyword">data</span> Type Count Produced <span class="code-snippet__keyword">by</span></span></code><code><span class="code-snippet_outer">========================================================</span></code><code><span class="code-snippet_outer"><span class="code-snippet__number">000</span>C <span class="code-snippet__number">1</span>C7B <span class="code-snippet__number">00000001</span> oldnames <span class="code-snippet__number">1</span> <span class="code-snippet__number">12</span> build <span class="code-snippet__number">7291</span></span></code><code><span class="code-snippet_outer"><span class="code-snippet__number">000</span>A <span class="code-snippet__number">1F</span>6F <span class="code-snippet__number">0000000</span>B cobj <span class="code-snippet__number">11</span> VC <span class="code-snippet__number">6</span> (build <span class="code-snippet__number">8047</span>)</span></code><code><span class="code-snippet_outer"><span class="code-snippet__number">000</span>E <span class="code-snippet__number">1</span>C83 <span class="code-snippet__number">00000005</span> masm613 <span class="code-snippet__number">5</span> MASM <span class="code-snippet__number">6</span> (build <span class="code-snippet__number">7299</span>)</span></code><code><span class="code-snippet_outer"><span class="code-snippet__number">0004</span> <span class="code-snippet__number">1F</span>6F <span class="code-snippet__number">00000004</span> stdlibdll <span class="code-snippet__number">4</span> VC <span class="code-snippet__number">6</span> (build <span class="code-snippet__number">8047</span>)</span></code><code><span class="code-snippet_outer"><span class="code-snippet__number">005</span>D <span class="code-snippet__number">0F</span>C3 <span class="code-snippet__number">00000007</span> sdk/imp <span class="code-snippet__number">7</span> VC <span class="code-snippet__number">2003</span> (build <span class="code-snippet__number">4035</span>)</span></code><code><span class="code-snippet_outer"><span class="code-snippet__number">0001</span> <span class="code-snippet__number">0000</span> <span class="code-snippet__number">0000004</span>D imports <span class="code-snippet__number">77</span> imports (build <span class="code-snippet__number">0</span>)</span></code><code><span class="code-snippet_outer"><span class="code-snippet__number">000</span>B <span class="code-snippet__number">2636</span> <span class="code-snippet__number">00000003</span> c++obj <span class="code-snippet__number">3</span> VC <span class="code-snippet__number">6</span> (build <span class="code-snippet__number">9782</span>)</span></code>
VC 2003 表明使用了在 VC 6 发布时还没有的 Windows API 通过 Windows SDK 导入。值得注意的是,经过研究人员分析,该样本与 Lazarus 使用的 Bluenoroff 样本的 Rich Header 相吻合,但却是故意诱导错误归因,攻击者定制修改了 Rich Header 以迷惑分析人员。
利用密钥对异或加密的数据(从 DanS(开始处)到 Rich(结尾处))解密后,计算 MD5 即为 richhash。
在 Dridex、Sathurbot 等许多样本中都经受住了考验。
缺点与对抗
- Enigma Protector、Themida 和 VMProtect 等商业壳保留原始文件的 Rich Header,可以在未加壳的样本和加壳的样本间展开双向狩猎
- 直接匹配异或的密钥可能会产生误报
- 攻击者可以定制化修改,不仅对抗检测也可能误导归因(不过,篡改的 Rich Header 也可作为检测的特征之一,如重复、无效的 Rich Header 值;无效的异或密钥等)
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/securelist.com/the</span>-devils-<span class="code-snippet__keyword">in</span>-the-rich-header/<span class="code-snippet__number">84348</span>/</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.virusbulletin.com/virusbulletin</span><span class="code-snippet__regexp">/2020/</span><span class="code-snippet__number">01</span>/vb2019-paper-rich-headers-leveraging-mysterious-artifact-pe-format/</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.sans.org/white</span>-papers/<span class="code-snippet__number">39045</span>/</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/infocon.hackingand.coffee/</span>Hacktivity/Hacktivity%<span class="code-snippet__number">202016</span>/Presentations/George_Webster-<span class="code-snippet__keyword">and</span>-Julian-Kirsch.pdf</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/github.com/</span>RichHeaderResearch/RichPE</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/link.springer.com/chapter</span><span class="code-snippet__regexp">/10.1007%2F978-3-319-60876-1_6</span></span></code>
richpvhash
背景
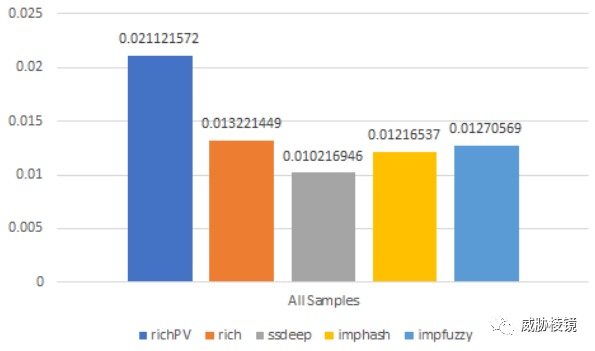
RichPV 从数据中剔除了易变的 Rich Header 字段(Product Count)再进行计算。查找在同一系统上编译、来自同一源代码项目的文件,更适合 RichPVHash。
原理
通过 2.5W 个 Korplug 样本测试后,对比如下所示:
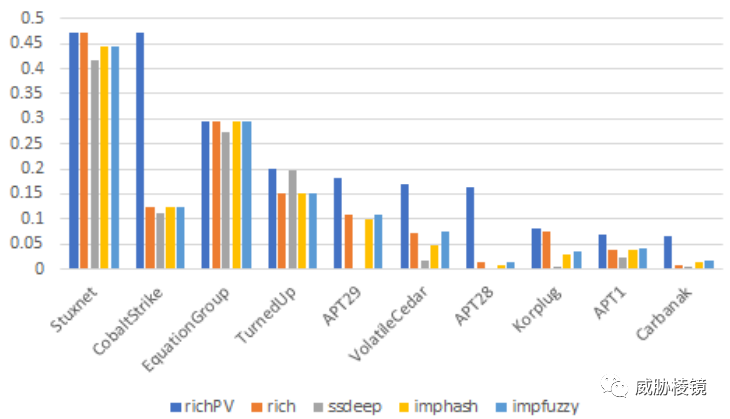
使用不同恶意软件对比:
缺点与对抗
- Rich Header 必须足够长才能产生哈希的差异
参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/modubyk/PE_Richness</span></span></code>
Machoc
简介
控制流图(CFG)实际上有着广泛的用途,比如识别已知函数等,将 CFG 应用于相似样本发现也是一大期待。2015 年的 SSTIC 上提出了 Machoc,使用数字表示对应的 CFG。
原理
基本方法:
- 使用 IDAPython 或者 miasm 提取样本的控制流图(CFG)
- 组成 CFG 的基本块按地址排序
- 将每个基本块翻译成标准格式
NUMBER:[c,][DST, ...];,其中NUMBER是基本块编号、c表示基本块中是否包含 call、DST为下一个基本块的编号 - 每个标准格式的内容串联起来再使用 Murmuhash3 计算哈希值
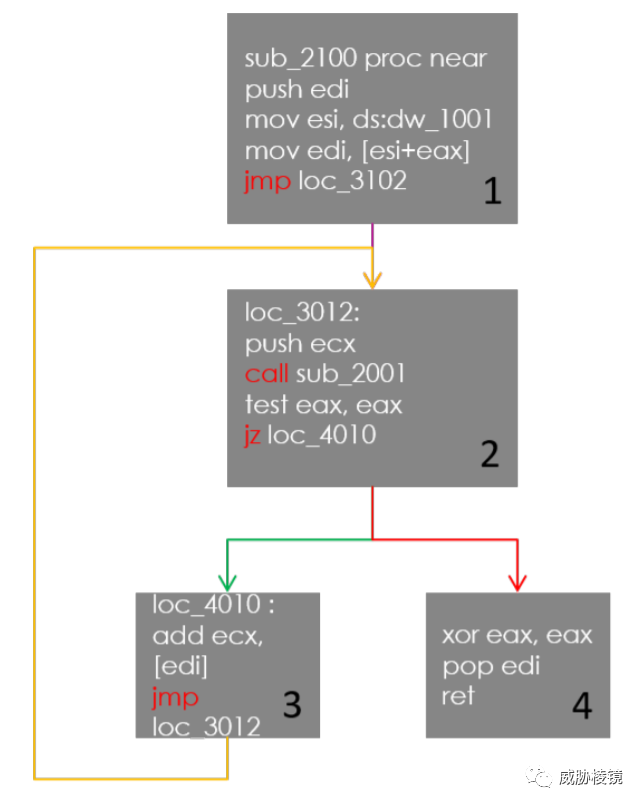
缺点与对抗
- 控制流混淆可以有效对抗此类分析
- 开销与资源要求较大
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/github.com/</span>ANSSI-FR/polichombr</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.sstic.org/media</span><span class="code-snippet__regexp">/SSTIC2016/</span>SSTIC-actes/demarche_d_analyse_collaborative_de_codes_malveill/SSTIC2016-Article-demarche_d_analyse_collaborative_de_codes_malveillants-chevalier_le-berre_pourcelot.pdf</span></code>
Machoke
原理
2017 年的 R2con 上提出了 Machoke,该方式与 Machoc 基本相同,区别只存在于使用 radare2 和 r2pipe 提取 CFG。
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.conix.fr/machoke</span>-hashing/</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/github.com/radareorg</span><span class="code-snippet__regexp">/r2con-2017/blob</span><span class="code-snippet__regexp">/master/talks</span><span class="code-snippet__regexp">/cfg-fuzzy-hash/</span>Machoke-cfg-based-fuzzy-hash.pdf</span></code>
TLSH
简介
趋势科技于 2013 年发布的哈希函数,全称为 Trend-Micro Locality Sensitive Hash。与 ssdeep 相比,TLSH 不依赖输入大小改变哈希长度(固定为 72 字符),且在恶意软件上能够具有更好的分类效果。
原理
趋势科技展示了强大的技术功底,为该哈希算法的设计写了一系列的文章,这些文章对想要设计新的模糊哈希算法的人来说是极其有帮助的。例如指出 SSDEEP 等模糊哈希算法的相似度度量方法构造的树是极度不平衡的,搜索性能退化成链表后可扩展性大大降低。再如 TLSH 可以应对恶意软件检测逃避技术,序列重排不会改变哈希。
这些技术要点便不再一一介绍了,设计上有着诸多考量和权衡,所有原理性设计都可以在相关的文章中找到细致的论述。总之,TLSH 搜索速度快,具有对数搜索时间;使用 Kskip-ngrams 鲁棒性更好;评估性能更高。
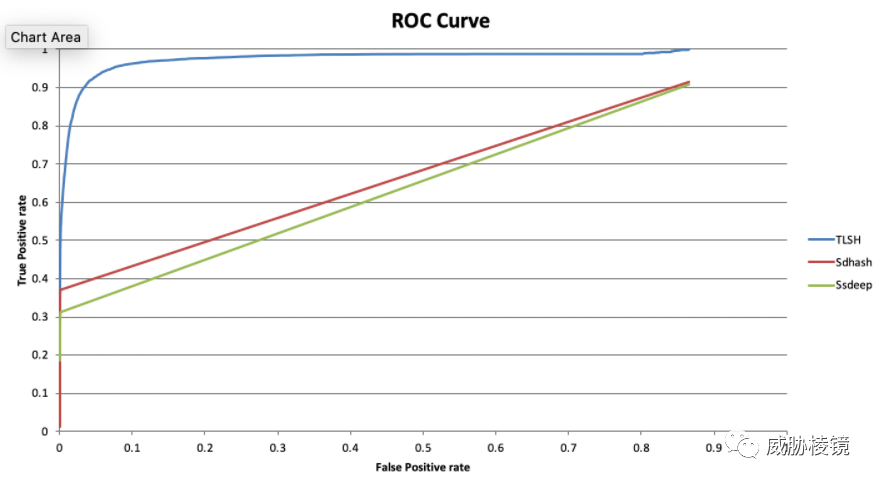
聚类样本画出树状图,以 Mirai 和 Gafgyt 为例:
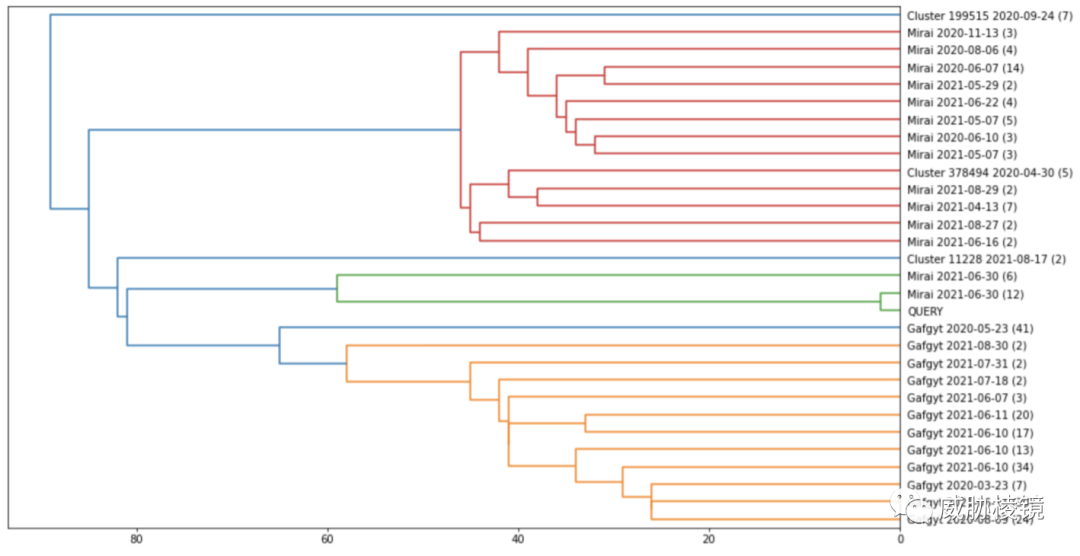
缺点与对抗
- 不适用检测包含,而是相似
-
最初的测试性能比 ssdeep 略低,但改进后应该更快了
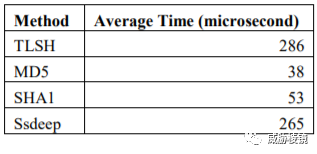
参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/trendmicro/tlsh</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//tlsh.org/index.html</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//documents.trendmicro.com/assets/wp/wp-locality-sensitive-hash.pdf</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//documents.trendmicro.com/assets/wp/wp-using-randomization-to-attack-similarity-digests.pdf</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//tlsh.org/papersDir/Design_TLSH_2021.pdf</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//tlsh.org/papersDir/COINS_2020_camera_ready.pdf</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//tlsh.org/papersDir/ISI_2020_final.pdf</span></span></code>
PEHash
简介
2008 年的 Usenix Security 文章,spamsum 和 mrshash 都展示了作用,提出了新的算法为 pehash。
原理
PEHash 不对完整文件计算哈希,而是对 PE 文件的部分字段进行哈希,这些字段在编译和加壳期间不易变化,如初始栈大小、堆大小等。
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.usenix.org/legacy</span><span class="code-snippet__regexp">/events/leet</span>09/tech/full_papers/wicherski/wicherski_html/index.html</span></code>
Authenticode PE Image Hash
简介
Authenticode 是微软用于验证数字签名的 PE 文件未被篡改的哈希值,可用于识别不同发布者签发的相同可执行文件。
原理
计算忽略 Authenticode 数据、指向 Authenticode 数据的指针和文件校验和的文件哈希值。
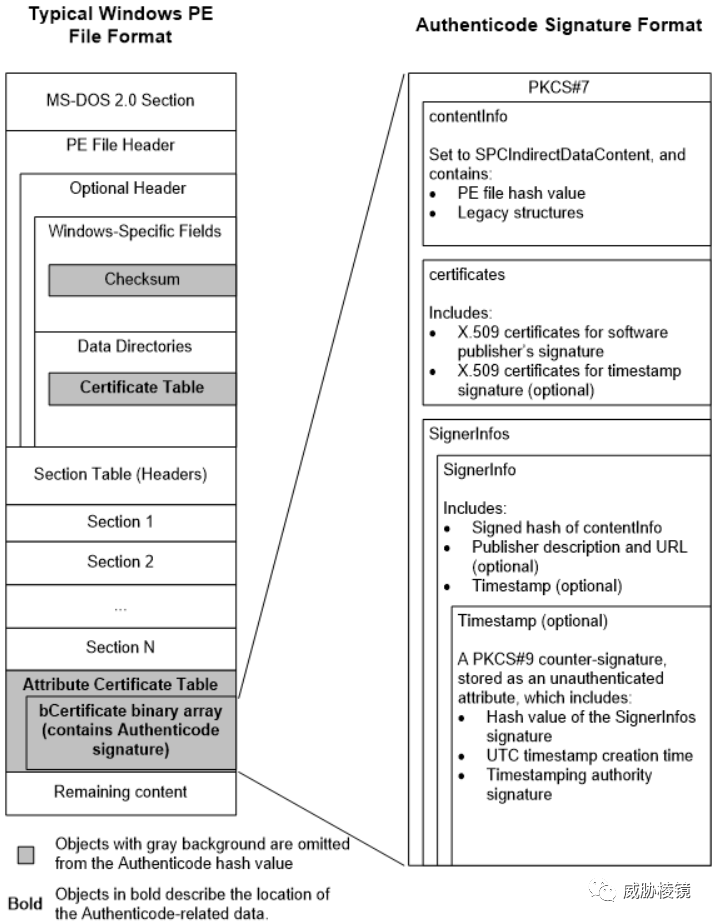
参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//www.blackhat.com/docs/us-16/materials/us-16-Nipravsky-Certificate-Bypass-Hiding-And-Executing-Malware-From-A-Digitally-Signed-Executable-wp.pdf</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//blog.reversinglabs.com/blog/breaking-the-windows-authenticode-security-model</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//www.avira.com/en/blog/undermining-authenticode</span></span></code>
TypeRefHash
简介
.NET 文件尽管也是 PE 格式,但导入表通常只包含 .NET 运行时(mscoree.dll),这就令 imphash 在 .NET 文件上失效了。与 imphash 类似,G Data Cyber Defense 针对 .NET 文件提出的导入表哈希就是 TypeRefHash。
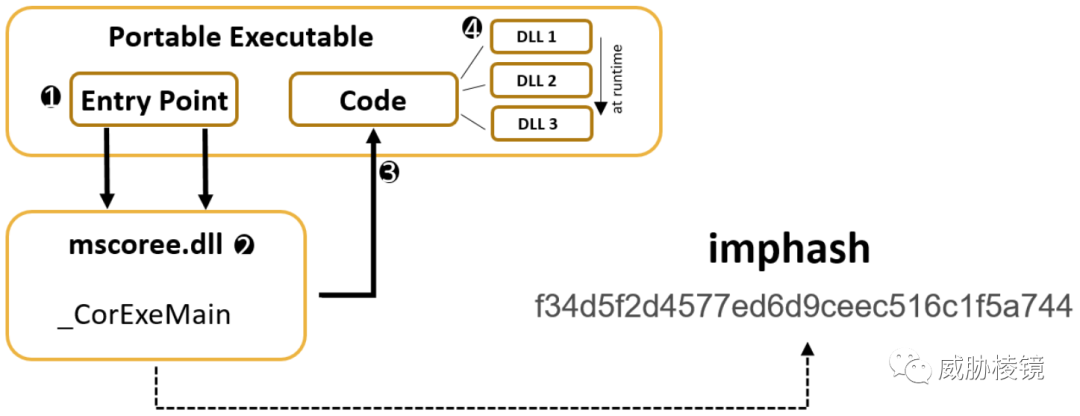
原理
.NET 引用的函数存储在所谓的元数据表中,将元数据表(排序后)中的命名空间(TypeNamespaces)和类型(TypeNames)连成字符串,然后计算 SHA-256 哈希值。
在对 AsyncRAT、Nanocore、QuasarRAT 等样本的评估中,足见其有效性:
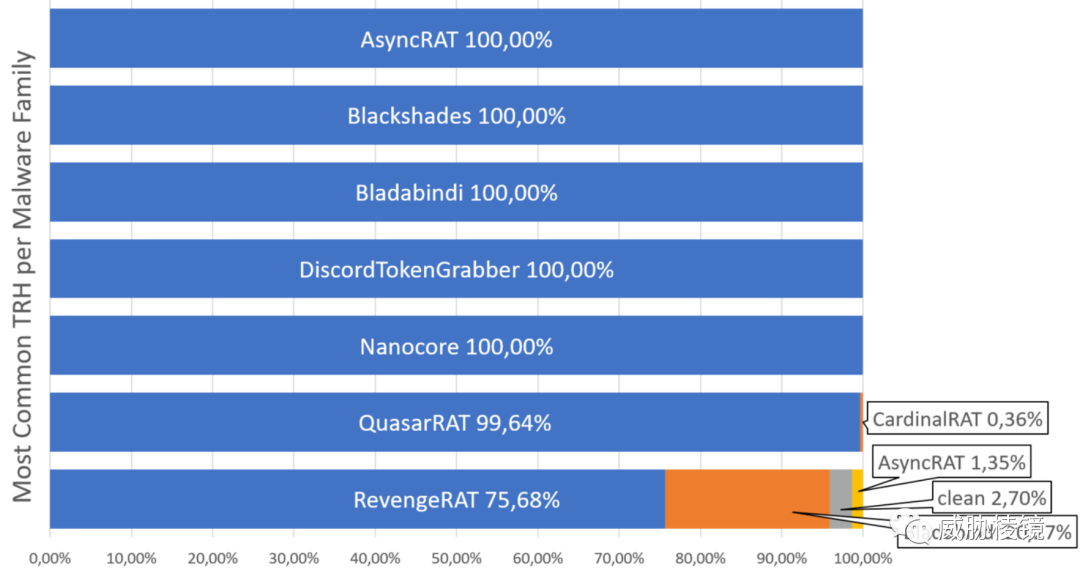
甚至包括 Agent Tesla 这种常见的 .NET 样本:
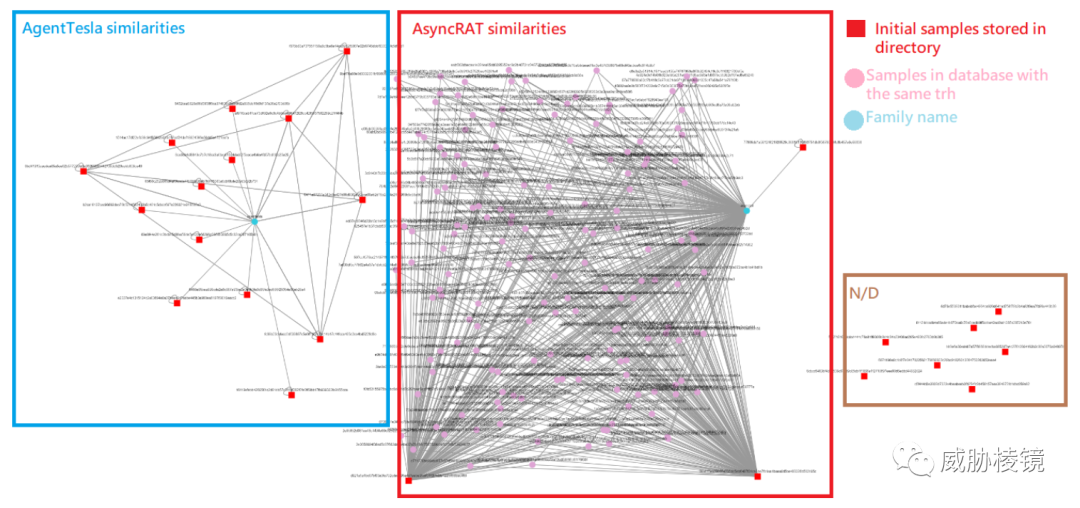
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.gdatasoftware.com/blog</span><span class="code-snippet__regexp">/2020/</span><span class="code-snippet__number">06</span>/<span class="code-snippet__number">36164</span>-introducing-the-typerefhash-trh</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/github.com/</span>GDATASoftwareAG/TypeRefHasher</span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/joseliyo-jstnk.medium.com/typeref</span>-hasher-the-imphash-solution-<span class="code-snippet__keyword">for</span>-samples-<span class="code-snippet__keyword">in</span>-net-<span class="code-snippet__number">9</span>aad14502bbf</span></code>
Dhash
简介
常有恶意软件将图标修改为 Office 等常用程序来欺骗用户,业界发现 PE 文件的图标可用于聚类相似样本。VirusTotal 和 Malwarebazaar 都支持 dhash 来跟踪相似样本,JoeSecurity 沙盒用使用 dhash,当然这种相似很多时候并非是同源的。
原理
将图片拉伸为固定大小,转换为灰度图片。将每个像素与右邻接像素比较,相比增加为 1,相比降低为 0。
由下可知,与类似的算法相比,dhash 在性能和效果之间取得了平衡。尽管 phash 的准确度很高,但性能太差,难以应对大规模样本。
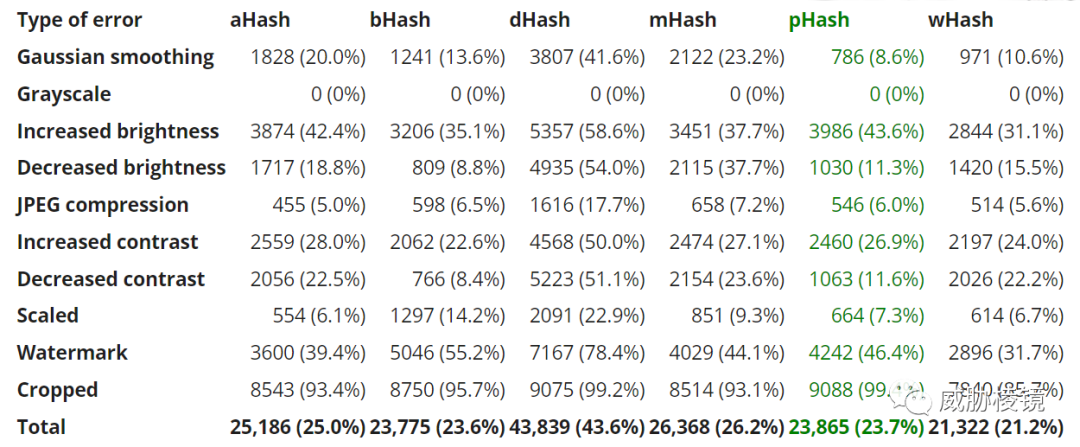
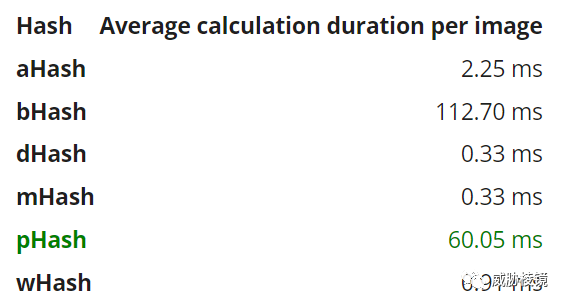
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/content-blockchain.org/research</span><span class="code-snippet__regexp">/testing-different-image-hash-functions/</span></span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.gdatasoftware.com/blog</span><span class="code-snippet__regexp">/2021/</span>09/an-overview-of-malware-hashing-algorithms</span></code>
vhash
简介
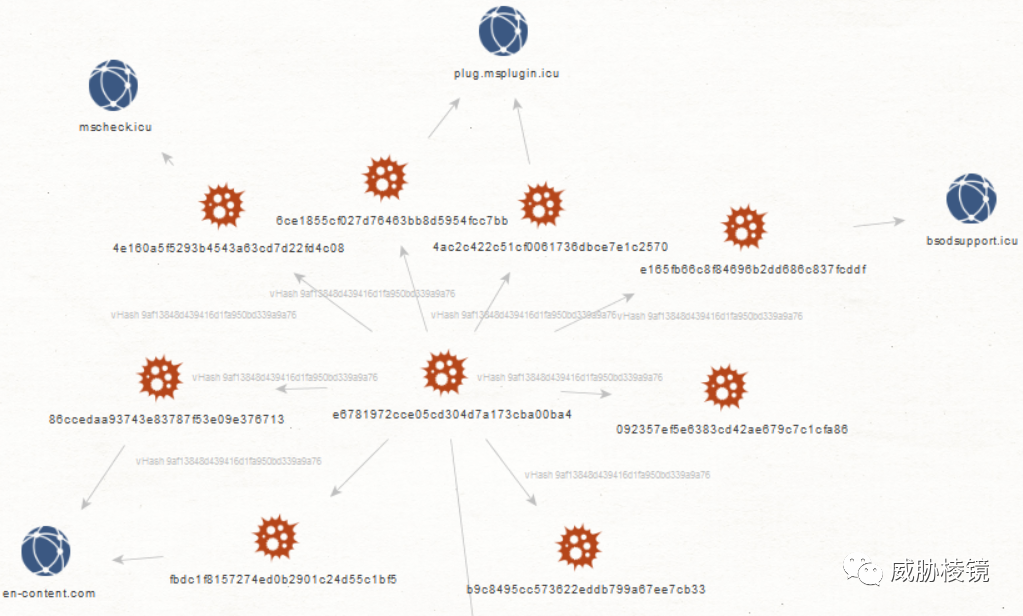
VirusTotal 在 2020 年提出的,基于文件结构特征计算的哈希。VirusTotal 并未在公开场合讲述该算法的更多细节,但很多安全研究人员均表示该算法有效性尚可。
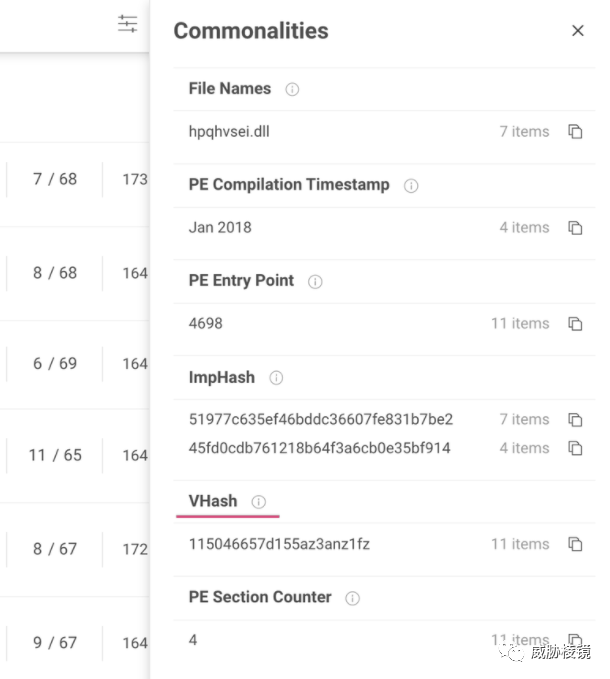
如可发现 Donot 的部分样本:
参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//twitter.com/cyb3rops/status/1223248099323367424</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/arieljt/VTvHash-Maltego</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//blog.virustotal.com/2020/11/why-is-similarity-so-relevant-when.html</span></span></code>
behash
简介
VirusTotal 基于样本在沙盒中的行为计算的哈希,与 vhash 类似的 VirusTotal 也从未在公开场合讲述该算法的更多细节,计算方式不得而知。
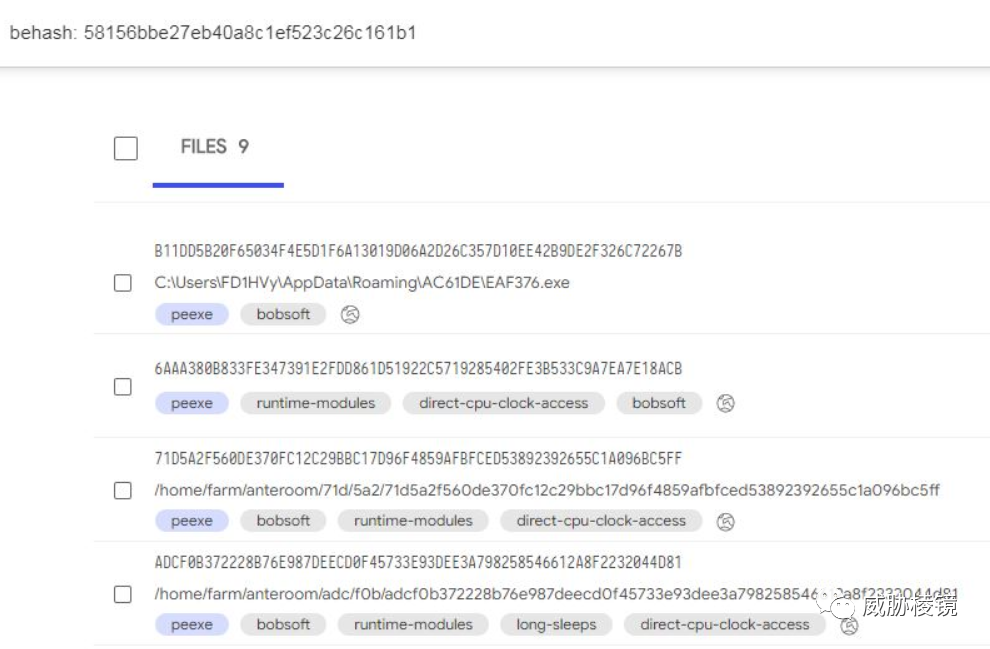
SDHash
简介
2010 年提出的模糊哈希算法,通过查找文件中随机发现的概率最低的序列,SDHash 弥补了 ssdeep 的准确性和可扩展性缺陷。
原理
SDHash 选择二进制文件中统计上不可能的特征,筛选出弱特征并使用布隆过滤器来支持不同大小对象的比较。
在 CODASPY 2018 中实验研究了四个哈希算法的效果,SDHash 的成绩相当好,但是比 TLSH 还是更差。
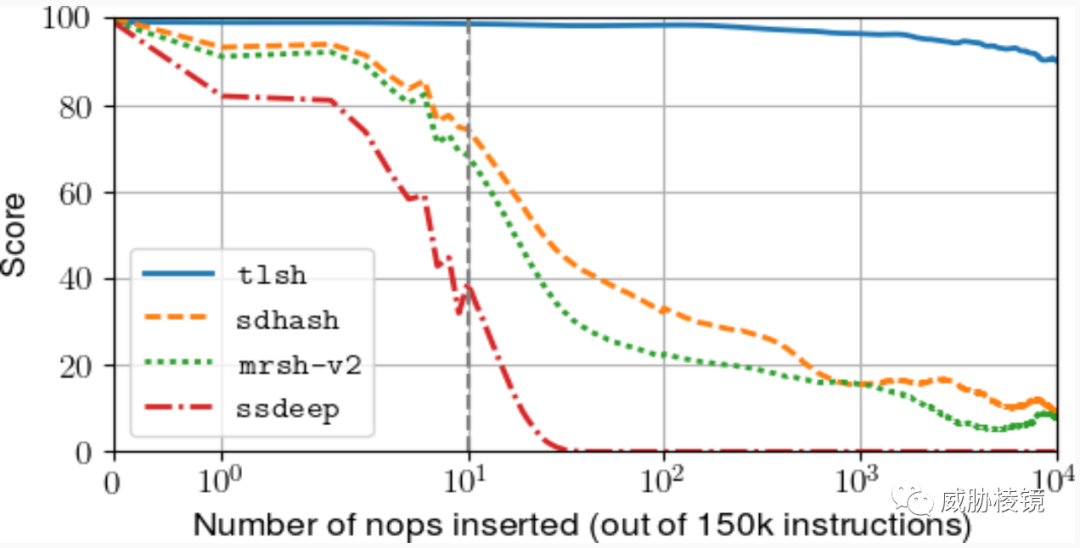
sdhash 比 ssdeep 准确度更高,其优势在片段比较而非全文件比较。
缺点和对抗
- 哈希大小会随着输入文件的大小而不断增加
- SDHash 研究发现了一些已知的漏洞
参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/sdhash/sdhash</span></span></code><code><span class="code-snippet_outer">《A collision attack on sdhash similarity hashing》</span></code><code><span class="code-snippet_outer">《Using randomization to attack similarity digests》</span></code><code><span class="code-snippet_outer">《Security and implementation analysis <span class="code-snippet__keyword">of</span> the similarity digest sdhash》</span></code>
TELFHash
简介
2020 年 4 月,趋势科技发布了 TELFHash(Trend Micro ELF Hash)。TELFHash 类似于 ELF 文件的导入表哈希,

原理
TELFHash 利用 TLSH 代替 MD5 作为哈希函数。
通过 ELF 文件的符号表获取 ELF 文件的导入函数,如下所示。
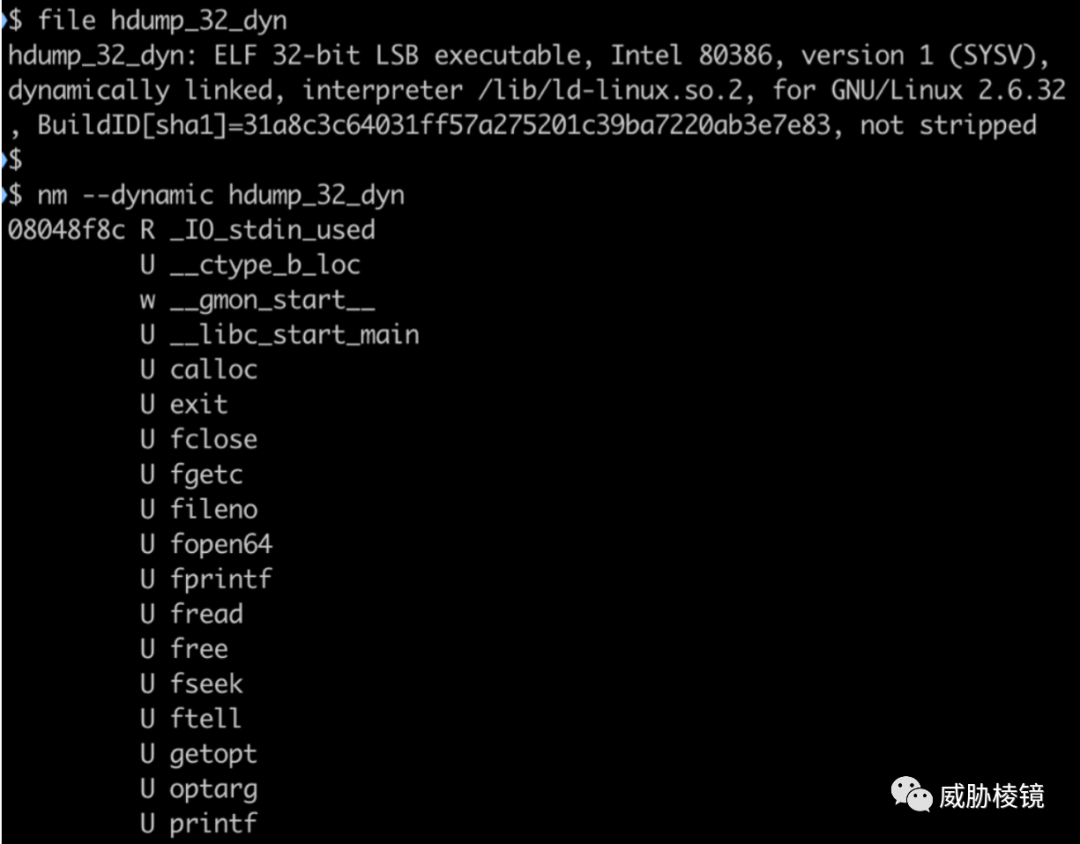
从 ELF 符号表中提取函数名称,再重新排序计算哈希。另外,stripped 的样本虽然没有符号表,但使用的外部函数相关的符号并没有从二进制文件中被删除:

为了兼容多种架构,忽略编译器添加的特定体系结构的函数:
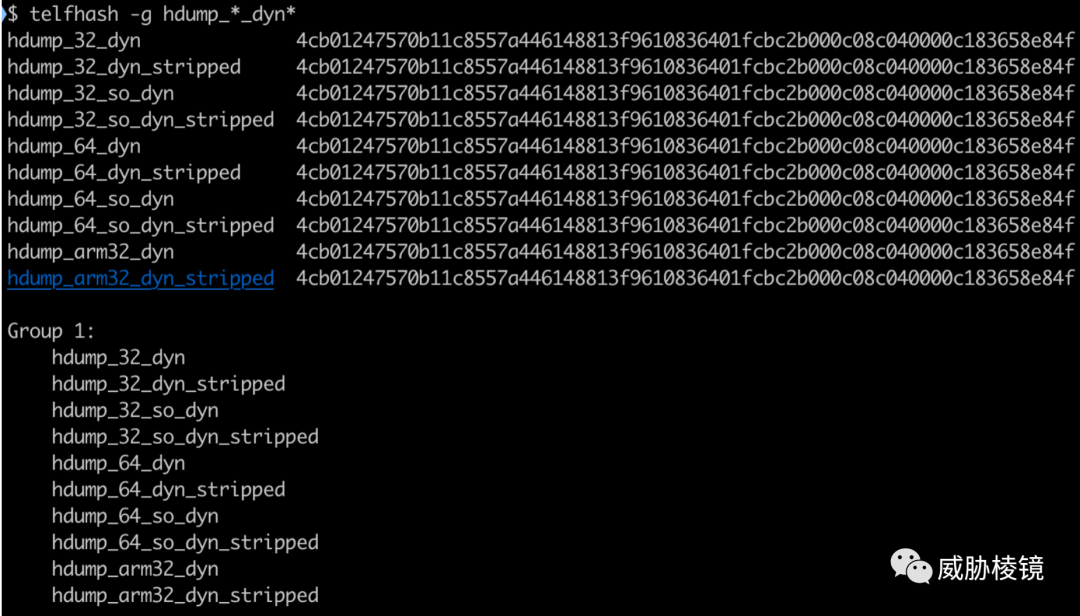
此时,已能够处理以下情况:
- 静态链接、带有符号表
- 动态链接、带有符号表
- 动态链接、无符号表

计算出来确实可见相关,但是静态链接、无符号表计算出的哈希和其他文件不相同,但仍然能够起效。
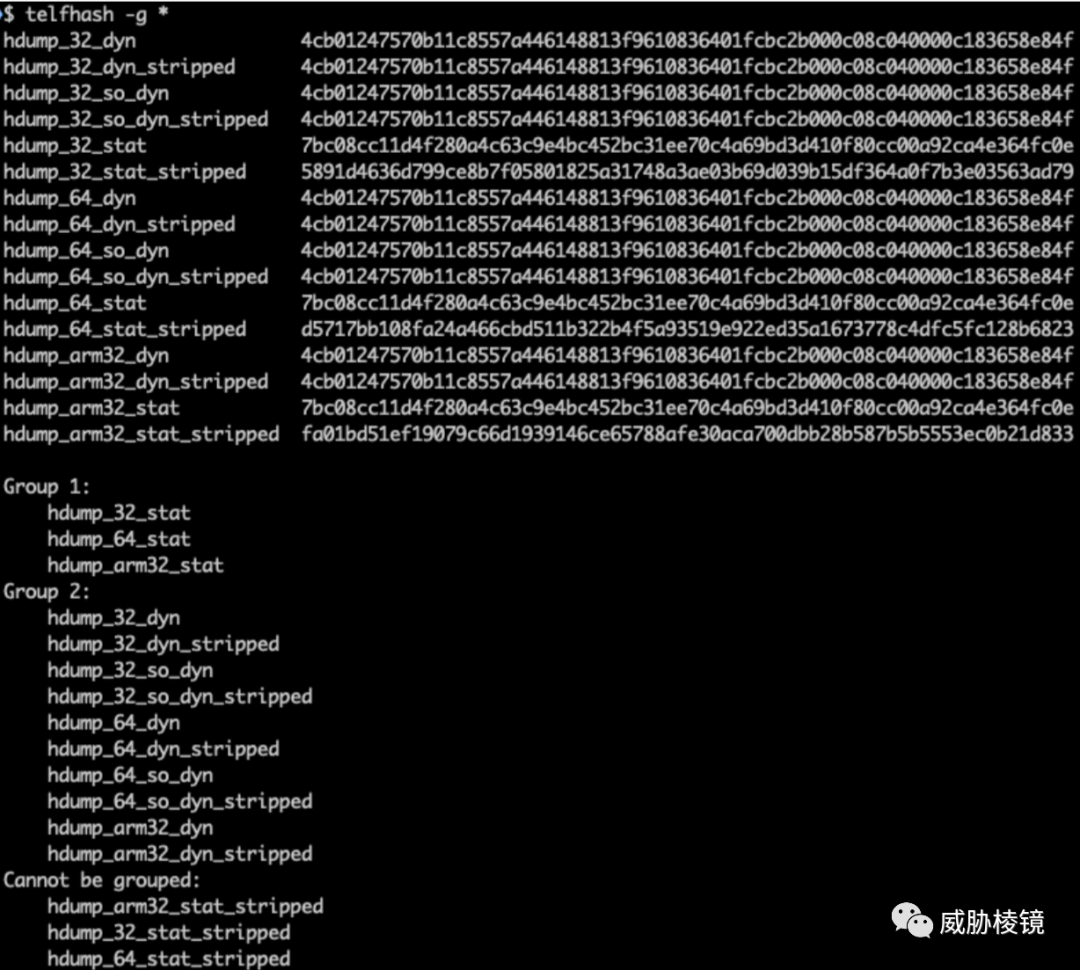
在 XorDDoS 上进行实验,结果如下所示:
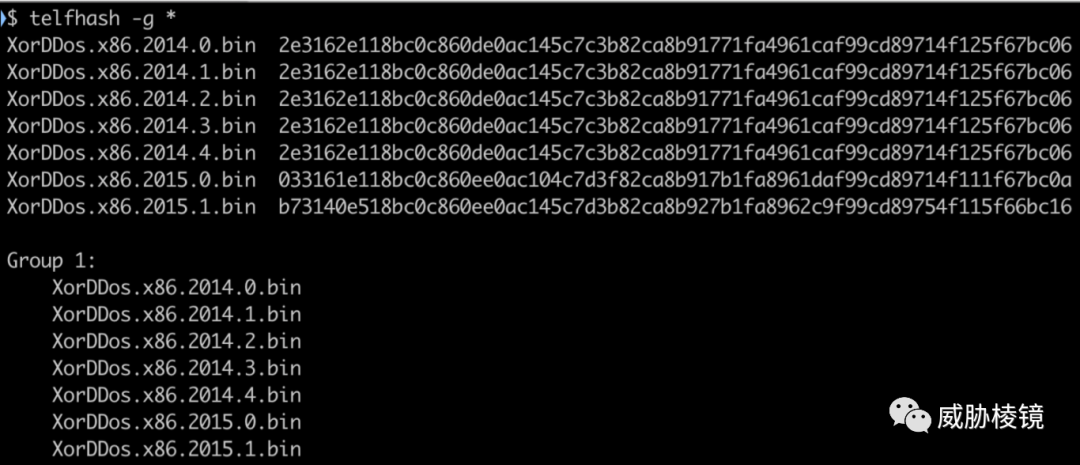
在 Momentum 上进行实验,结果如下所示:

参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//www.trendmicro.com/en_us/research/20/j/virustotal-now-supports-trend-micro-elf-hash.html</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/trendmicro/telfhash</span></span></code>
Lempel-Ziv Jaccard
简介
2017 年提出、用于为任意字节序列计算距离的算法,设计用于替换归一化压缩距离(Normalized Compression Distance,NCD)。
原理
比较之下,Lempel-Ziv Jaccard 比 ssdeep 和 SDHash 都要更好:
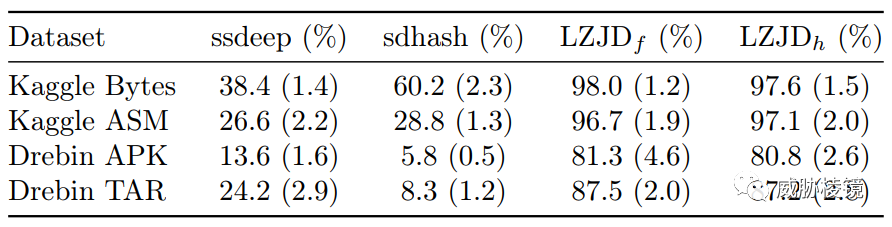
参考来源(部分)
<code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/EdwardRaff/LZJD</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/EdwardRaff/jLZJD</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//github.com/EdwardRaff/pyLZJD</span></span></code><code><span class="code-snippet_outer">http:<span class="code-snippet__comment">//www.edwardraff.com/publications/alternative-ncd-lzjd.pdf</span></span></code><code><span class="code-snippet_outer">https:<span class="code-snippet__comment">//arxiv.org/abs/1708.03346</span></span></code>
mvHash-B
简介
mvhash 是基于多数投票的模糊哈希,分为 mvHash-B 与 mvHash-L 两种。其中 mvHash-B 算法是在 2013 年提出的。
原理
mvHash-B 将输入转换为等长度的 0x00 或者 0xFF 字节序列,在用 RLE 编码压缩后再利用改进的布隆过滤器生成等长的哈希值(2018 bit)。
根据测试,mvHash-B 比 sdHash 更好:

参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/ieeexplore.ieee.org/abstract</span><span class="code-snippet__regexp">/document/</span><span class="code-snippet__number">6568552</span></span></code><code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/ntnuopen.ntnu.no/ntnu</span>-xmlui/bitstream/handle/<span class="code-snippet__number">11250</span>/<span class="code-snippet__number">144008</span>/KPAstebol.pdf</span></code>
mrsh-v2
简介
2012 年发布的 MRSH-V2(Multiresolution Similarity Hashing-v2)相比 MRSH 在效率和性能上均有所改进。其整合了 ssdeep 和 sdhash,声称改进了 ssdeep 的安全性。
原理
在七个字节的滑动窗口上使用滚动哈希,再使用 FNV-1A 哈希函数对每个块进行哈希,并将结果分成五个子哈希,每部分的 k×log2(m) 位用于寻址布隆过滤器。
缺点和对抗
- 尽管速度比 sdhash 更快,但是准确率和召回率都更差。
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/link.springer.com/chapter</span><span class="code-snippet__regexp">/10.1007/</span><span class="code-snippet__number">978</span>-<span class="code-snippet__number">3</span>-<span class="code-snippet__number">642</span>-<span class="code-snippet__number">39891</span>-<span class="code-snippet__number">9_11</span></span></code>
其他
业界也在积极探索其他解决方案,例如微软为模糊哈希设计 word embeddings 再结合神经网络 perceptron 进行检测。
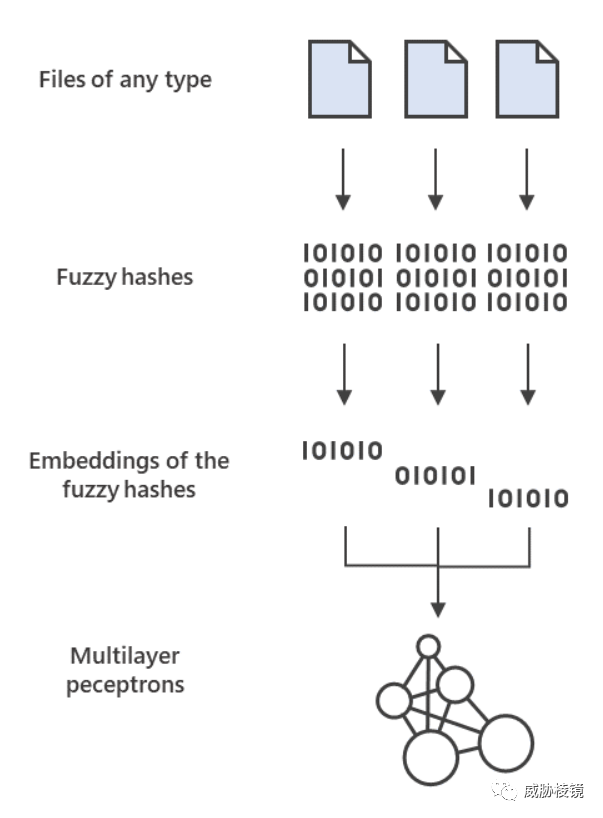
参考来源(部分)
<code><span class="code-snippet_outer"><span class="code-snippet__symbol">https:</span>/<span class="code-snippet__regexp">/www.microsoft.com/security</span><span class="code-snippet__regexp">/blog/</span><span class="code-snippet__number">2021</span>/<span class="code-snippet__number">07</span>/<span class="code-snippet__number">27</span>/combing-through-the-fuzz-using-fuzzy-hashing-<span class="code-snippet__keyword">and</span>-deep-learning-to-counter-malware-detection-evasion-techniques/</span></code>
模糊哈希
以上有很多哈希函数为模糊哈希,回头总结一下。总的来说,模糊哈希可分为以下四种类型:
上下文触发分段哈希(Context Triggered Piecewise Hashing,CTPH)
为了避免哈希随文件变大而无限变长,块大小不固定而是依赖触发点,触发点依据样本大小计算而来,如 ssdeep。尽管样本对齐问题并不像 BHB 那样明显,但其实仍然限于大小差不多的相对较小的文件,为了提高检测能力就可以像 ssdeep 一样使用两个不同的值作为块大小的触发点。
基于块的哈希(Block-Based Hashing,BHB)
为固定大小的块创建哈希,但通常用于数字取证,如 dcfldd。因为文件越大,哈希越长,这样是没法应用在样本狩猎的应用场景下的。
不可能统计特征(Statistically-Improbable Features,SIF)
根据文件非偶然出现的特征进行比较,如 sdhash 使用熵来计算特征。这样保证了文件的修改如果不影响该类特征,哈希就不会受到影响。
基于块的重构(Block-Based Rebuilding,BBR)
使用辅助数据重构文件,如 mvhash-B 通过多数投票将文件的每个字节与相邻字节进行比较,将文件的每个字节映射到 FF 或 00 上,再由字节序列组成哈希。
大尺度下相似文件检索
在样本量巨大的情况下,一一比较每个哈希计算相似程度的方式太耗时了。而且很多哈希的比较方法还是独特设计的,这都有可能带来很大的计算开销。传统的精确匹配可以利用平衡树等结构构建索引,保证单个查询的复杂度低于暴力搜索的 O(log(n))。为了提高匹配检索的效率,提出了几类方法:
- 分布式 P2P 搜索:将哈希按照固定的距离计算方式存储在特定的节点中,分布式处理检索相似的哈希。为了可靠性,必须多出额外的存储以及冗余的节点。
- 使用 Nilsimsa 的分布式哈希表 DHTnil,误报率很高,且查询时间复杂度并不低于一一比对
- 使用 ssdeep 的分布式哈希表 iCTPH,查询的时间复杂度也不低于一一比对
- 索引搜索:构建索引,在索引上进行精确匹配以大大加速检索过程,例如 n-gram。
- 过滤器搜索:通过过滤器的数据结构来快速判断是否存在但不能精确给出,而且对内存的占用极大。例如 Bloom 过滤器、Cuckoo 过滤器。
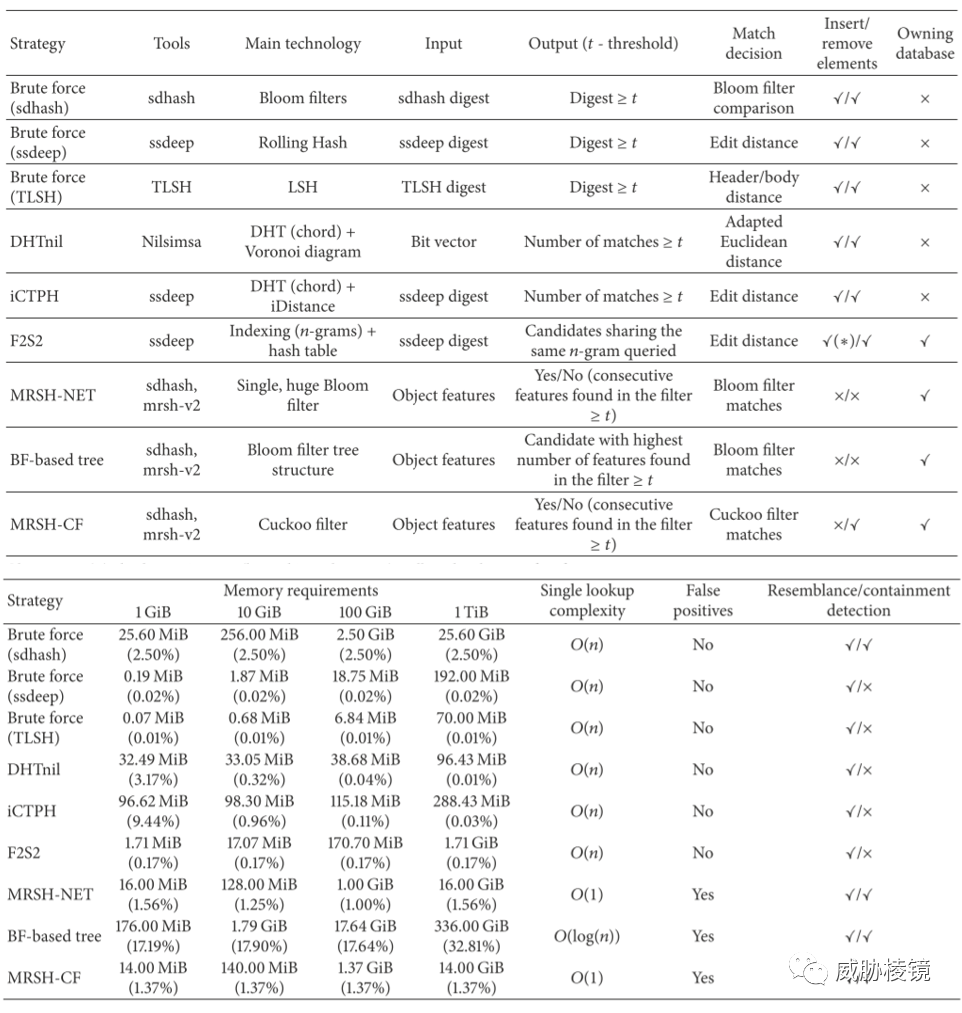
结合之前介绍的方式,通用且高效的方法应该就是构建索引(例如 ngram)来做。需要处理大量的样本的情况下,可以参考自己进行设计。
转自:https://mp.weixin.qq.com/s/7WrlFUepch6JhU2NhdSyJw
转载请注明:jinglingshu的博客 » 狩猎样本的哈希游戏