一、规则 > 模型 > 脚本 > 算法
安全检测其实就是对安全大数据的分析,其实现的方法有很多例如在IDS、EDR可以有对应的语法及引擎直接配置规则,也可以采集遥测数据到数仓里面用ES、Flink做分析。安全检测的场景大多数都是可以用规则实现;如果涉及大数据量的过滤、关联、统计等分析基本的规则无法满足则可以考虑大数据计算引擎写一些SQL模型;涉及到复杂的逻辑判断、多个系统数据关联SQL无法便利满足的条件下可以使用脚本去实现检测逻辑;另外某些安全场景如自学习安全模型的相似度、网络隧道信息熵普通的规则和SQL模型无法满足需要使用一些算法。
安全规则学习成本低、计算成本低,同时规则易于管理,也便于安全团队的多数人一起协同开发。SQL模型相对于相对于规则学习门槛更高一些,模型的运维部署比安全规则成本更高,很多安全规则引擎其实底层也都是大数据引擎,规则就是抽象的SQL。脚本灵活且团队的人写个python基本问题都不大,但是缺点在于标准化比较差,不利于统一管理和协同,脚本可以是定时查询任务可以是实时消费SDK也可以是FlinkUDF。算法模型相对于前面几类学习成本和计算成本就更高了,一般团队内部会有专注于算法的同事跟检测模型开发的同事协同开发。
举一些检测场景的例子,终端/主机类的检测规则可以在两个地方运行,一部分规则可以运行在Agent,这样做的好处是可以比较容易的关联多级进树(时至今日仍然有很多产品只能支持两级、三级进程 其中不乏业内优秀产品),安全规则开发可以直接产品页面或者基于产品语法编写规则;另一种是基于采集上来的遥测数据做实时或者离线分析,通常来说遥测数据里面只附带父子进程数据,此时编写的规则语法类似于SIEM/SOC的大数据规则或SQL,通常来说基于单条进程、网络、文件日志获得的告警可能会是误报、上下文不足或被攻击者恶意绕过。
└ Image: \xxx\cmd.exe
Cmd: “C:\xxx\cmd.exe” /c ipconfig /all
└ Image: \xxx\ipconfig.exe
Cmd: ipconfig /all
如上面这个是一个EDR网络环境发现的异常告警详情(ATT&CK T016 System Network Configuration Discovery),安全运营人员看到后会一脸懵逼,而且每天会有大量的这种告警,运营人员可以去跟设备归属人确认是否为本人之行,往往很多这样的指令是有设备自身的软件进程之行,归属人也说不知道,进一步运营人员去数仓查询对应的上下文排除异常或者误报,枯燥且乏味。对于这个困境解决方案有几个,第一个是前面说的Agent规则,告警会自带一些上下文,第二个是写SQL Join基本上Splunk、Humio、Elastic、Flink都是支持的,这个方案有一点缺点是Join过多性能损耗大时间窗口不能开的过长,办公网场景尚且合适生产网很多父进程是n年前启动的无法关联;第三个是直接使用图数据库,图SQL天然支持多级Join关联;第四个就是前面提到的脚本,当匹配到告警时候用脚本多次查询存储遥测数据的数仓,多次查询避免一次Join的性能瓶颈,脚本更为灵活,此时的脚本你可以是Flink里面的UDF,也可以是外挂的SOAR脚本富化告警。如下告警一眼就能看出是否异常。
└ Image: \xxx\cmd.exe
Cmd: “C:\xxx\cmd.exe” python3 \desktop\money\money.py
└ Image: \xxx\python3.exe
Cmd: “C:\xxx\python3.exe” \desktop\money\money.py
└ Image: \xxx\malicious.exe
Cmd: “C:\xxx\malicious.exe” xxxxxx
└ Image: \xxx\cmd.exe
Cmd: “C:\xxx\cmd.exe” /c ipconfig /all
└ Image: \xxx\ipconfig.exe
Cmd: ipconfig /all
三、可观测可消费、分布式可扩展
这两句都是从检测架构层面的理念特别是对于海量数据大架构的场景,于是合并到了一起,那时做的威胁感知要覆盖非常多的Region,每个Region会有NIDS、FW、CWPP等各种安全产品,除了要自动分析每类安全产品告警还要分析这些安全产品以及业务的原始日志,每个Region每天的日志量可以达到好几个T,一般方案有两种,一种是将数据传输到一个Region进行统一的威胁感知,另一种是在各Region放置服务器做存储和计算使用,计算的威胁感知结果传输到一个Region的SOC里面处理,当然每个Region也可以有自己的SOC。
所以刚刚说的就是可消费,在分布式业务的场景下做到每处数据可消费,具体实现来说可以在每个Region都准备多台机器,在这些机器上部署K8S,关于数仓、计算引擎、自动化代码都可以部署在K8S上,在基础网络层面我们可以只对机器点对点打通必要的端口,安全分析的基础工具都在K8S内部通信,这样即保证网络打通少也避免后续安全模型和基础设施不断变化要一直打通网络。具体应用场景例如K8S上有套Flink,安全模型开发人员可以使用Zeeplin开发模型并且下发安全分析任务到任意节点,如果性能不够了可以任意扩展多个计算节点;我们的扫描器可以根据安全组变化即时在任意的Region任意的内网发起扫描;SOAR的每条告警可以触发多个Playbook并发执行且可分发到任意Region的Worker上;全局自生产了威胁情报可以根据K8S上编排调度系统对接到各Region防火墙路由器WAF下发阻断,也可以去各数仓发起自动调查自动回溯的任务;这些说的都是分布式可扩展。
还差一个可观测没说,如果出现了安全事件需要安全分析师人工去分析原始日志,每天可能出现N个安全事件在不同Region,如果需要安全分析师VPN拨入不同的Region去登入不同的数仓平台会极为麻烦。所以我们不光要可消费,我们可以在K8S上的数仓检索页面连接到每个数仓的底座,只要勾选不同的连接器即可到对应的地方观测即可。看过之前公众号文章的同学可能都读过多级SOC架构的文章,里面面对几十个全球分布式的SOC当时就沿用了这套架构的思路。
这部分说的不是那么直观,放两张图可以参考一下,前面一张是很久之前做过的分布式攻击压制系统图,后面一张是多级SOC的架构图。
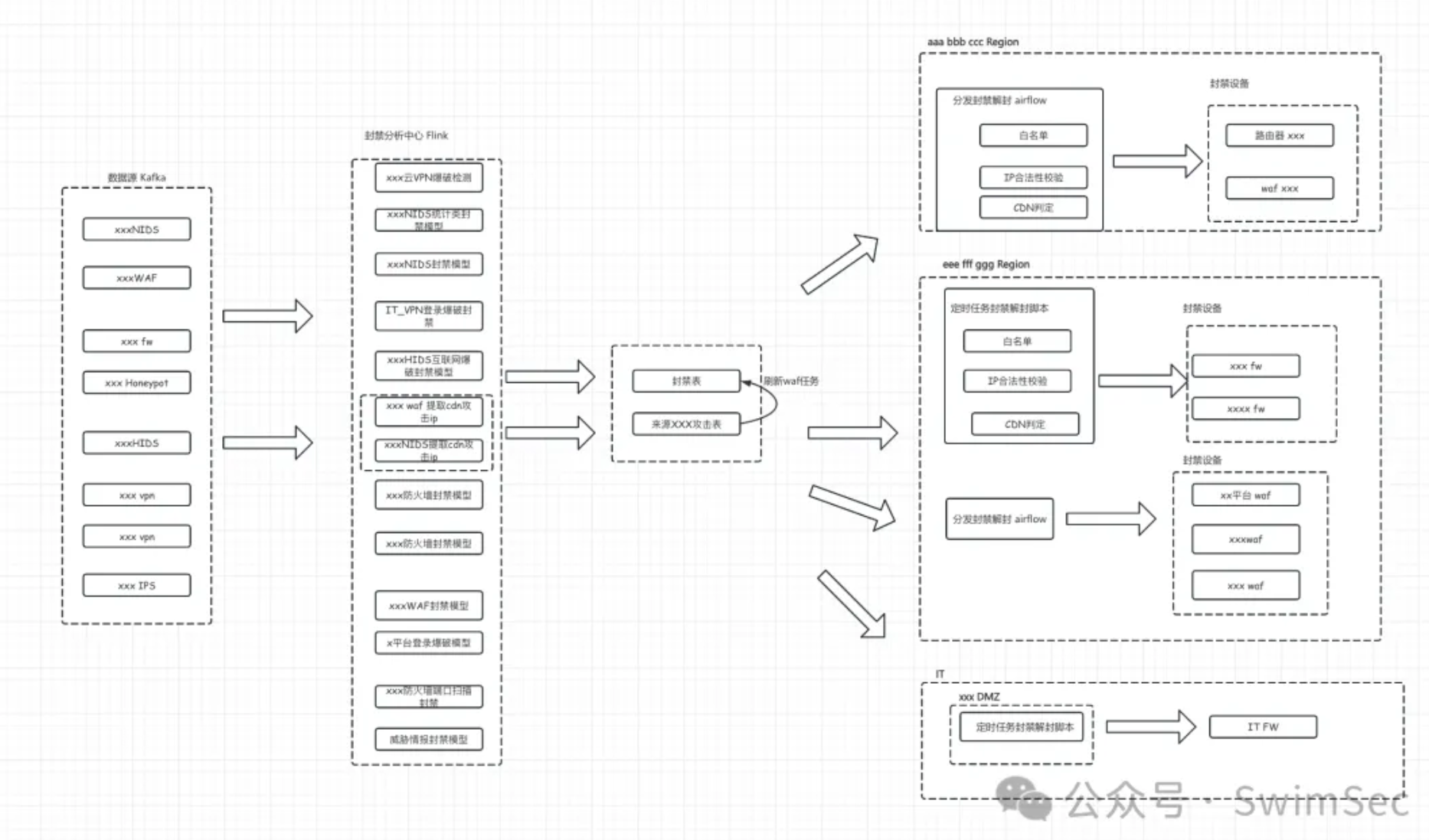
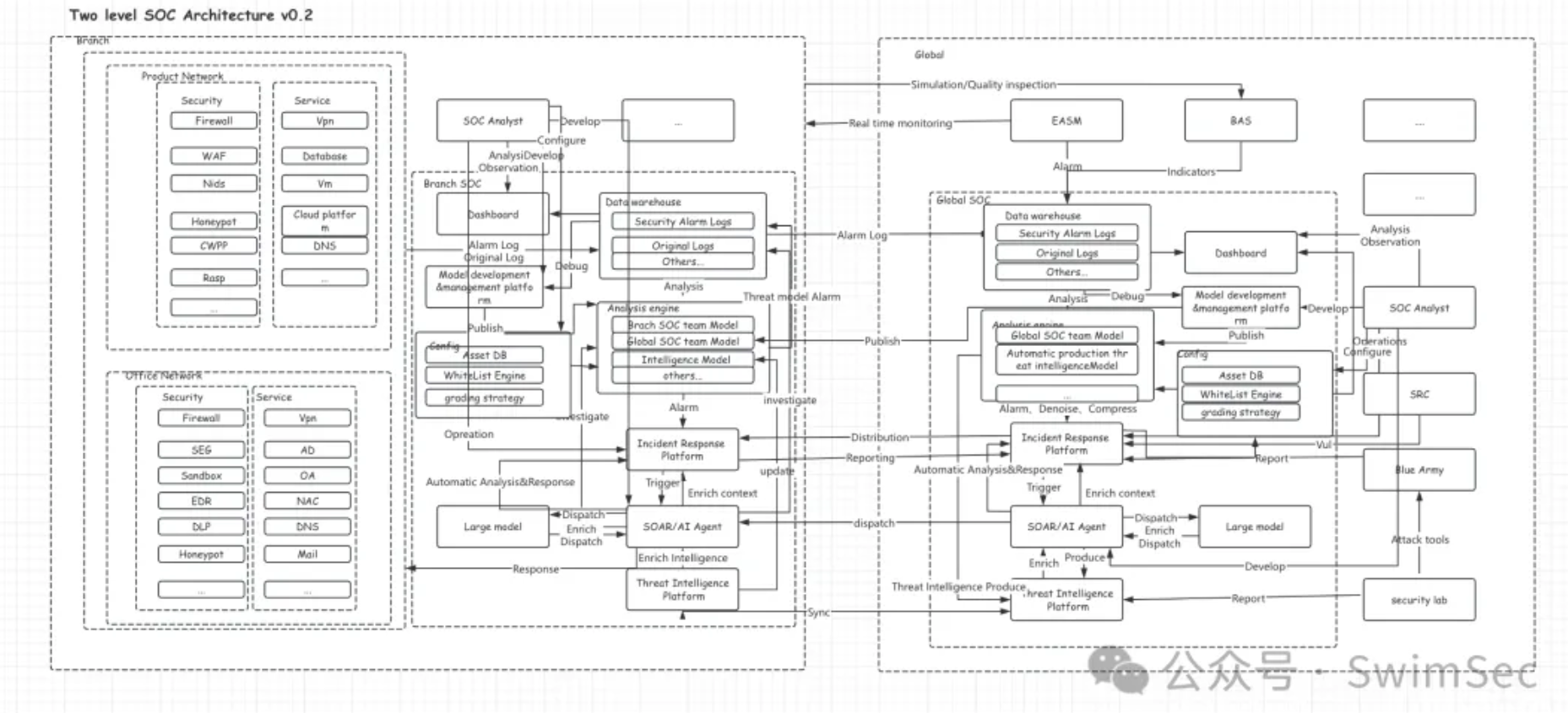
四、安全模型开发的过程就是告警量不断增多,经过优化告警量不断降低,反复这个过程
在安全建设的初始阶段,首先安全产品原生的告警做一定的自动化分析,从海量的告警中筛选出安全运营人员分析处置;进一步逐渐的发现有很多的薄弱点是安全产品无法覆盖的、或者是特定对手的某些TTP检测能力要细化,此时我们需要根据遥测数据做检测能力的增强。随着安全产品、安全模型数量的增多告警量会不断上升,其中伴随着很多的噪音误报,安全运营工程师苦不堪言,安全模型开发工程师需要根据告警的情况进一步优化模型(很多时候安全运营和模型开发都是同一批人,自己看不惯的告警自己需要优化咯),告警量不断的降低,最终在SIEM/SOC看到的全是有效告警,最好的效果是每个事件的每个阶段每个行为都有对应的告警,且每个行为告警只需要一条无多余的冗余告警。
具体在告警量优化的过程中有很多方法,无论是产品的原始告警还是遥测数据的安全模型告警方法类似。首先是筛选告警,要知道哪些告警需要安全运营人员去关注,很多地方一天告警上亿条不是每条告警都需要人去分析,以NIDS为例一般需要根据告警的状态、告警的类型、告警的位置去筛选如攻击成功、失陷、内网攻击、来自VPN的攻击、内网向外攻击、存在漏洞等等;有了筛选还不行,还需要聚合,例如一个主机感染了木马和僵尸网络,木马远控每天的告警条数能达到几百条,如果一台主机感染后在SIEM/SOC产生几百条告警是无法接受的,此时需要根据失陷告警名称资产按天聚合,那么此时每天只产生一条告警;有时候告警聚合也会失效,例如某台内网主机失陷了,疯狂扫描内网的主机,内网扫描类聚合策略一般是源目地址告警名称等,该场景下也会产生大量的告警涌入SIEM/SOC,此时需要告警压制策略如内网扫描告警根据源资产每天超过三条即压制。
经过上述一系列漏斗筛选告警到分诊的数量一般是安全运营工程师可接受的范围,但是告警里面依然有很多的噪音,我们可以借助更多自动化的手段自动分析告警自动忽略告警自动处置告警,这样告警的数量可以进一步降低。自动分析首先就是白名单,白名单可以是多个条件的组合,例如某个资产某种行为白名单忽略;第二步是自动富化上下文分析,例如第一个例子中关联EDR告警进程树,某类进程树的可以告警可以忽略,进一步可以关联告警文件投递沙箱结果、域名和IP的情报、恶意行为前后的Bash流水、关联计划任务的内容、行为在全局的流程程度等,就算无法完全自动处置告警也可以加速分析,现在也可以交由大模型分诊了。第三是做一些告警的自动处置,例如某个漏洞需要修复自动创建工单通知给资产责任人,修复完成只需要资产责任人回复已修复触发扫描器自动验证,验证完成关闭工单,全程告警是不需要安全运营工程师参与的,所以这部分告警数量可以忽略,很多权限变更、高危操作类的告警也类似。
告警的数量降低了,日常就是根据情报、真实的CASE、BAS、红蓝对抗去不断的寻找检测体系的薄弱点,分优先级去覆盖提升检测能力。
这篇文字是今天下午开始写的,中间玩玩手机吃吃饭摸摸鱼这会儿已经到了半夜,脑袋有点晕晕的写不动了,印象中祥哥还有很多令我印象深刻的语录如我们检测开发只用最顶级的项目,如apache xxx,参考业界的最佳实践,google的威胁感知是xxx自动化是xxx;如果内网发生扫描,蜜罐没有感知一定是部署方案有问题,我们通过xxx可以实现全员蜜罐;安全检测和产品最开始就是模仿优秀的实践然后迭代创新,有时候把别的领域的技术理念放到安全领域发现效果很好这就是创新,如xxxwaf的词法分析最早是数据库的词法解析 等等。这些思路和理念伴随着我后面几年的工作非常受用,同时我也经常将这些思路传播给身边的人,感谢在工作生活中一路上遇见的贵人,用技术正能量感染大家~
转自:https://mp.weixin.qq.com/s/qChHVfAVRIFdEQ_S1DeK9A
转载请注明:jinglingshu的博客 » 检测语录小记