原文:https://ops.tips/blog/how-linux-tcp-introspection/
在本文中,我们将为读者介绍套接字在准备接受连接之前,系统在幕后做了哪些工作,以及“准备好接受连接”倒底意味着什么 。为此,我们将深入介绍bind(2)、listen(2)和accept(2)等函数的内部运行机制,看看它们为构造套接字数据结构做了哪些方面的工作。
如果您想了解netstat命令幕后的故事,请一定坚持读到最后!
创建TCP套接字
为了建立TCP连接,我们必须创建相应的TCP套接字。所以,我们首先要做的,就是在服务器端创建一个套接字,同时,在客户端创建另一个套接字。
这一步至关重要,因为这实际上就是为通信的双方创建相应的端点。
在这一步中,通信双方调用的函数是相同的,即都是socket(2)函数。
int
main (int argc, char** argv)
{
// Create a socket in the AF_INET (ipv4)
// communication domain, of type `SOCK_STREAM`
// (sequenced, reliable, two-way, connection-based
// stream - yeah, tcp), using the most adequate
// protocol (that last argument - 0).
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd == -1) {
perror("socket");
return 1;
}
return 0;
}
在上面的代码中,唯一让人感到神秘的地方恐怕就是socket(2)了!
请一定先阅读 How Linux creates Sockets。
一旦用适当的协议族和具体协议创建好套接字之后,我们就可以考察如何利用一个与具体协议有关的调用来建立有效连接了。
将套接字绑定到地址
在绑定之前,我们创建的套接字虽然存在于给定的命名空间中,但尚未为其分配相应的地址——底层数据结构已经就绪(已分配),但还没有定义相关的语义。
函数bind(2) 的作用是,将在用户空间指定的地址分配给从socket(2)函数接收的文件描述符所引用的套接字。
/*
* bind - bind a name to a socket.
*/
int bind(
// The socket that we created before and which we
// want to associate an address with.
int sockfd,
// Address varies depending on the address family.
//
// `struct sockaddr` defines a generic socket address,
// but given that each family carries its own address
// definition, we need to specialize this struct with
// a `struct` that suits our protocol.
const struct sockaddr *addr,
// Size of the address structure pointed to by addr.
socklen_t addrlen);
这个函数特别有趣:在接收地址数据时,为了做到尽可能地通用,它预期收到的参数有两个,一个参数是指向某内存块的指针,另一个参数表示内存块的大小。
USERSPACE:
bind( socket, [ ..... piece of memory ...... ], size of the piece of memory)
"hey kernel, here's some chunk of memory that corresponds
to something that the socket's family understand; and
btw, its size if `N`".
KERNELSPACE:
oh, thx! I'll let `af_inet` know about it!
>> grabs the memory by copying it to kernelspace;
>> forwards it to the af_inet implementation of `bind`.
例如,就这里来说(IPv4),我们可以监听所有接口(0.0.0.0)上的1337端口,为此,只需为结构体sockaddr_in填充相应的协议族、端口和地址信息即可:
/*
* server_bind - binds a given socket to a specific
* port and address.
* @listen_fd: the socket to bind to an address.
*/
int
server_bind(int listen_fd)
{
// Structure describing an internet socket
// address (ipv4).
struct sockaddr_in server_addr = { 0 };
int err = 0;
// The family that the address belongs to.
// AF_INET: ipv4 "internet" addresses.
server_addr.sin_family = AF_INET;
// The IPV4 address in network byte order (big endian)
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
// The service port that we're willing to
// bind the socket to (in network byte order).
server_addr.sin_port = htons(PORT);
err = bind(listen_fd,
(struct sockaddr*)&server_addr,
sizeof(server_addr));
if (err == -1) {
perror("bind");
fprintf(stderr, "Failed to bind socket to address\n");
return err;
}
}
虽然我们没有在堆中为结构体sockaddr_in分配内存空间(可以通过malloc或类似函数),但是,我们仍然创建了一块具有相应的大小的内存供其引用(因此,我们可以将其传递给bind函数)。
此外,虽然bind(2)预期接收的数据为一个sockaddr结构体,但实际上,我们几乎可以将任何具有addrlen规定大小的内存块传递给它,即其大小不必与sockaddr相同。
例如,我们不妨考察一下IPv4和IPv6协议族之间的差异。
在这两种情况下,都需调用bind(2)函数来为套接字分配地址,当然,与IPv4相比,IPv6具有更大的地址空间,因此,自然需要更大的结构体。
// Generic `sockaddr`. A pointer to
// a struct like this is expected by the
// `bind` syscall.
//
// size: 16B
struct sockaddr {
sa_family_t sa_family; // 2B
char sa_data[14]; // 14B
}
// The socket address representation of an
// IPv4 address.
//
// size: 16B
struct sockaddr_in {
sa_family_t sin_family; // 2B
in_port_t sin_port; // 2B
struct in_addr sin_addr; // 4B
// Just add the rest that is left
// (padding it for reasons I don't know).
unsigned char sin_zero[8]; // 8B
}
// The socket address representation of an
// IPv6 address.
//
// size: 28B
struct sockaddr_in6 {
sa_family_t sin6_family; // 2B
in_port_t sin6_port; // 2B
uint32_t sin6_flowinfo; // 4B
struct in6_addr sin6_addr; // 16B
uint32_t sin6_scope_id; // 4B
};
最重要的是,相关协议系列低层的绑定操作的具体实现是如何处理这样的内存块的——该内存块中应该是地址(无论协议系列认为地址是什么,这里都应该是地址)。
内核如何处理传递给bind函数的地址
跟踪上面程序的绑定操作,我们可以看到AF_INET套接字的bind(2)函数的堆栈跟踪信息:
# Trace the `inet_bind` method, the one that
# gets called whenever a `bind` is called
# on a socket that has been created for
# the `af_inet` family (regardless of the
# type - SOCK_STREAM or SOCK_DATAGRAM).
trace -K inet_bind
PID TID COMM FUNC
28700 28700 bind.out inet_bind
inet_bind+0x1 [kernel]
sys_bind+0xe [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
仔细考察上面的内容,我们就能理解整个过程是如何进行的。
首先,让我们从提供bind(2)函数的系统调用功能的方法sys_bind开始,我们可以看到:
- 查找为进程文件描述符保存的底层套接字;
- 将内存从用户空间复制到内核空间;然后
- 让低层的套接字协议族来处理绑定操作。
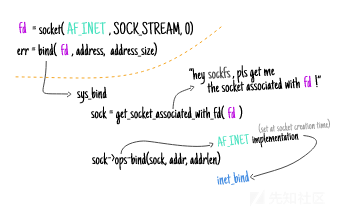
这个系统调用的定义位于net/socket.c文件中:
/*
* Bind a name to a socket. Nothing much to do here since it's
* the protocol's responsibility to handle the local address.
*
* We move the socket address to kernel space before we call
* the protocol layer (having also checked the address is ok).
*/
SYSCALL_DEFINE3(bind,
int, fd,
struct sockaddr __user*, umyaddr,
int, addrlen)
{
// Reference to the underlying `struct socket`
// associated with the file descriptor `fd` passed
// from userspace.
struct socket* sock;
struct sockaddr_storage address;
int err, fput_needed;
// Retrieve the underlying socket from the
// file descriptor.
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
// Copy the address to kernel space.
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (err >= 0) {
// Call any security hooks registered for
// the `bind` operation
err = security_socket_bind(
sock, (struct sockaddr*)&address, addrlen);
if (!err) {
// Perform the underlying family's
// bind operation.
err = sock->ops->bind(
sock, (struct sockaddr*)&address, addrlen);
}
}
fput_light(sock->file, fput_needed);
}
return err;
}
实际上,这里最能引起我关注的是:所有这些系统调用都提供了audit_或security_方法。
看起来,Linux安全模块的“命”是这些hook给的(参见 Linux Security Modules: General Security Hooks for Linux):
Linux安全模块(LSM)框架提供了一种机制,可以通过新的内核扩展来hook各种安全检查。
这太有意思了!
有了内核中的套接字地址,以及与找到的文件描述符关联的套接字结构,现在是时候调用sock->ops->bind了(就本例来说,即inet_bind)。
考虑到bind函数基本上就是一个“修改器”函数,从某种意义上说,它的用途就是改变socket结构中的某些内部字段,所以,在考察这些修改是如何进行的之前,先让我们来弄清楚修改的是哪些字段。
/**
* Higher-level interface for any type of sockets
* that we end up creating through `sockfs`.
*/
struct socket {
// The state of the socket (not to confuse with
// the transport state).
//
// Note.: this is an enumeration of five possible
// states:
// - SS_FREE = 0 not allocated
// - SS_UNCONNECTED, unconnected to any socket
// - SS_CONNECTING, in process of connecting
// - SS_CONNECTED, connected to socket
// - SS_DISCONNECTING in process of disconnecting
//
// Given that we have already called `socket(2)`, at
// this point, we're clearly not in the `SS_FREE` state.
socket_state state;
// File description (kernelspace) associated with
// the file descriptor (userspace).
struct file *file;
// Family-specific implementation of a
// network socket.
struct sock *sk;
// ...
};
/**
* AF_INET specialized representation of network sockets.sockets.
*
* struct inet_sock - representation of INET sockets
*
* @sk - ancestor class
* @inet_daddr - Foreign IPv4 addr
* @inet_rcv_saddr - Bound local IPv4 addr
* @inet_dport - Destination port
* @inet_num - Local port
* @inet_saddr - Sending source
* @inet_sport - Source port
* @saddr - Sending source
*/
struct inet_sock {
struct sock sk;
#define inet_daddr sk.__sk_common.skc_daddr
#define inet_rcv_saddr sk.__sk_common.skc_rcv_saddr
#define inet_dport sk.__sk_common.skc_dport
#define inet_num sk.__sk_common.skc_num
__be32 inet_saddr;
// ...
};
根据这些定义,我们可以推断出哪些字段需要进行修改:与源地址和源端口相关的字段。
一旦开始进行检查并调用各种安全相关的hook,bind函数就会开始修改sock中的相关字段。
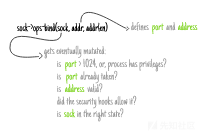
通过阅读下面的代码,我们可以明白倒底进行了哪些修改(详见net/ipv4/af_inet.c文件):
// `AF_INET` specific implementation of the
// `bind` operation (called by `sys_bind` after
// retrieving the underlying `struct socket`
// associated with the file descriptor supplied
// by the user from `userspace`).
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
// Retrieves the `struct sock` associated with the non-family
// specific representation of a socket (`struct socket`).
struct sock *sk = sock->sk;
// Cast the socket to the `inet-specific` definition
// of a socket.
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
unsigned short snum;
// ...
// Make sure that the address supplied is
// indeed of the size of a `sockaddr_in`
err = -EINVAL;
if (addr_len < sizeof(struct sockaddr_in))
goto out;
// Make sure that the address contains the right family
// specified in its struct.
if (addr->sin_family != AF_INET) {
err = -EAFNOSUPPORT;
if (addr->sin_family != AF_UNSPEC || addr->sin_addr.s_addr != htonl(INADDR_ANY))
goto out;
}
// ...
// Grab the service port as set in the address
// struct supplied from userspace.
snum = ntohs(addr->sin_port);
err = -EACCES;
// Here is where we perform the check to make sure
// that the user has the necessary privileges to
// bind to a privileged port.
if (snum && snum < inet_prot_sock(net) &&
!ns_capable(net->user_ns, CAP_NET_BIND_SERVICE))
goto out;
// Can't bind after the socket is already active,
// of if it's already bound.
err = -EINVAL;
if (sk->sk_state != TCP_CLOSE || inet->inet_num)
goto out_release_sock;
// Set the source address of the socket to the
// one that we've supplied.
inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr;
if (chk_addr_ret == RTN_MULTICAST || chk_addr_ret == RTN_BROADCAST)
inet->inet_saddr = 0;
/* Make sure we are allowed to bind here. */
// CC: this is where you can retrieve a "random" port
// if you don't specify one.
if (
(snum || !inet->bind_address_no_port) && // has a port set?
sk->sk_prot->get_port(sk, snum) // was able to grab the port
) {
inet->inet_saddr = inet->inet_rcv_saddr = 0;
err = -EADDRINUSE;
goto out_release_sock;
}
// ...
// Set the source port to the one that we've
// specified in the address supplied.
inet->inet_sport = htons(inet->inet_num);
inet->inet_daddr = 0;
inet->inet_dport = 0;
// ...
return err;
}
搞定!
至此,bind(2)就完成了它的使命:为内核中的底层套接字结构提供了一个地址(在用户空间指定)。
注意,目前我们仍然没有在/proc/net/tcp中看到任何套接字。关于这一点,我们稍后再详细介绍!
让套接字进入被动状态
一旦我们为套接字设置了地址,接下来就是让它扮演服务器或客户端的角色。
也就是说,它需要将自己设置为侦听传入的连接,或者启动与正在侦听的其他人的连接。
在这里,我们通过listen(2)来扮演服务器角色,即让自己来监听客户端连接。
// "listen for connections on a socket."
int listen(
// File descriptor refering to a
// socket of type SOCK_STREAM or
// SOCK_SEQPACKET.
int sockfd,
// Maximum length to which the queue
// of pending connections for `sockfd`
// can grow.
int backlog);
至于我们是如何在用户空间完成这一任务的,具体见下列代码:
int
server_listen(int listen_fd)
{
int err = 0;
err = listen(listen_fd, BACKLOG);
if (err == -1) {
perror("listen");
return err;
}
}
根据手册页的说法:
listen()将sockfd引用的套接字标记为被动套接字,即使用accept(2)接受传入的连接请求的套接字。
那么,“标记”究竟意味着什么呢?
此外,如果传入“backlog”参数的话,会出现什么情况呢?
解开系统调用listen的神秘面纱
与bind(2)非常相似,系统调用listen(2)的实现代码的作用是,找出与用户空间文件描述符相关联的套接字(与调用该系统调用的进程相关联),进行一些必要的检查,然后让协议族的实现代码来处理相关的语义。
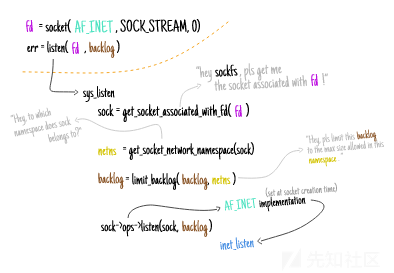
该系统调用的实现代码,详见net/socket.c文件:
SYSCALL_DEFINE2(listen,
int, fd,
int, backlog)
{
struct socket *sock;
int err, fput_needed, somaxconn;
// Retrieve the underlying socket from
// the userspace file descriptor associated
// with the process.
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
// Gather the `somaxconn` paremeter globally set
// (/proc/sys/net/ipv4/somaxconn) and make use of it
// so limit the size of the backlog that can be
// specified.
//
// See https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)
backlog = somaxconn;
// Run the security hook associated with `listen`.
err = security_socket_listen(sock, backlog);
if (!err) {
// Call the ipv4 implementation of
// `listen` that has been registered
// before at `socket(2)` time.
err = sock->ops->listen(sock, backlog);
}
fput_light(sock->file, fput_needed);
}
return err;
}
非常有趣的是,我发现backlog只会受到网络命名空间的SOMAXCONN参数集的限制,而不是整个系统的限制。
我们能验证一下吗?当然!
小结
在本文中,我们为读者介绍套接字在准备接受连接之前,系统在幕后做了哪些工作,以及“准备好接受连接”倒底意味着什么 。由于篇幅较长,这里分为两个部分进行翻译,更多精彩内容,将在下篇中继续为读者介绍。
揭开Linux 系统上TCP的 bind 和 listen函数的神秘面纱(下)
原文:https://ops.tips/blog/how-linux-tcp-introspection/
在本文中,我们为读者介绍套接字在准备接受连接之前,系统在幕后做了哪些工作,以及“准备好接受连接”倒底意味着什么 。由于篇幅较长,本文分为上下两篇进行翻译,这里为下篇。
检查listen函数的backlog参数是否受具体域名空间所限
如果该参数确实由具体网络命名空间决定的话,那么,我们可以设法进入某个命名空间,设置某个限值,然后,让外部看到的却是另一个限值:
# Check the somaxconn limit as set in the
# default network namespace
cat /proc/sys/net/core/somaxconn
128
# Create a new network namespace
ip netns add mynamespace
# Join the network namespace and then
# check the value set for `somaxconn`
# within it
ip netns mynamespace exec \
cat /proc/sys/net/core/somaxconn
128
# Modify the limit set from within the
# network namespace
ip netns mynamespace exec \
/bin/sh -c "echo 1024 > /proc/sys/net/core/somaxconn"
# Check whether the limit is in place there
ip netns mynamespace exec \
cat /proc/sys/net/core/somaxconn
1024
# Check that the host's limit is still the
# same as before (128), meaning that the change
# took effect only within the namespace
cat /proc/sys/net/core/somaxconn
128
所以,通过/proc,我们可以看到相关的sysctl参数的情况,但是,它们真的就位了吗?
要解决这个问题,我们首先需要了解如何收集为给定套接字设置的backlog参数的限值。
利用procfs收集TCP套接字的相关信息
通过/proc/net/tcp,我们可以看到当前名称空间中所有的套接字。
通常,我们可以利用这个文件找到所需的大部分信息。
该文件包含了一些非常有用的信息,比如:
- 连接状态;
- 远程地址和端口;
- 本地地址和端口;
- 接收队列的大小;
- 传输队列的大小。
例如,在我们让套接字进入监听状态之后,就可以通过它来查看相关信息了:
# Retrieve a list of all of the TCP sockets that
# are either listening of that have had or has a
# established connection.
hexadecimal representation <-.
of the conn state. |
|
cat /proc/net/tcp |
.---------------. .----.
sl | local_address | rem_address | st | tx_queue rx_queue
0: | 00000000:0016 | 00000000:0000 | 0A | 00000000:00000000
*---------------* *----*
| |
*-> Local address in the format *-.
<ip>:<port>, where numbers are |
represented in the hexadecimal |
format. |
.--------------------*
|
The states here correspond to the
ones in include/net/tcp_states.h:
enum {
TCP_ESTABLISHED = 1,
TCP_SYN_SENT,
TCP_SYN_RECV,
TCP_FIN_WAIT1,
TCP_FIN_WAIT2,
TCP_TIME_WAIT, .-> 0A = 10 --> LISTEN
TCP_CLOSE, |
TCP_CLOSE_WAIT, |
TCP_LAST_ACK, |
TCP_LISTEN, ------*
TCP_CLOSING,
TCP_NEW_SYN_RECV,
TCP_MAX_STATES,
};
当然,这里并没有看到为侦听套接字配置的backlog参数,这是因为该信息与处于LISTEN状态的套接字密切相关,当然,目前来说,这只是一个猜测。
那么,我们该如何进行检测呢?
检查侦听套接字的backlog参数的大小
为了完成这项任务,最简便的方法是使用iproute2中的ss命令。
现在,请考虑以下用户空间代码:
int main (int argc, char** argv) {
// Create a socket for the AF_INET
// communication domain, of type SOCK_STREAM
// without a protocol specified.
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if (sock_fd == -1) {
perror("socket");
return 1;
}
// Mark the socket as passive with a backlog
// size of 128.
int err = listen(sockfd, 128);
if (err == -1) {
perror("listen");
return 1;
}
// Sleep
sleep(3000);
}
运行上面的代码后,执行ss命令:
# Display a list of passive tcp sockets, showing
# as much info as possible.
ss \
--info \ .------> Number of connections waiting
--tcp \ | to be accepted.
--listen \ | .-> Maximum size of the backlog.
--extended | |
.--------..--------.
State | Recv-Q || Send-Q | ...
LISTEN | 0 || 128 | ...
*--------**--------*
在这里,我们之所以使用的是ss,而非/proc/net/TCP,主要是因为后者的最新版本没有提供套接字的backlog方面的信息,而ss却提供了。
实际上,ss之所以能够提供这方面的信息,是因为它使用了不同的API从内核中检索信息,即它没有从procfs中读取信息,而是使用了netlink:
Netlink是一种面向数据报的服务。[...]用于在内核和用户空间进程之间传输信息。
鉴于netlink可以与许多不同内核子系统的通信,因此,ss需要指定它打算与哪个子系统通信——就套接字来说,将选择sock_diag:
sock_diag netlink子系统提供了一种机制,用于从内核获取有关各种地址族套接字的信息。
该子系统可用于获取各个套接字的信息或请求套接字列表。
更具体地说,允许我们收集backlog信息的是UDIAG_SHOW_RQLEN标志:
UDIAG_SHOW_RQLEN
...
udiag_rqueue
For listening sockets: the number of pending
connections. [ ... ]
udiag_wqueue
For listening sockets: the backlog length which
equals to the value passed as the second argu‐
ment to listen(2). [...]
现在,再次运行上一节中的代码,我们可以看到,这里的限制确实视每个命名空间而定。
好了,我们已经介绍了这个backlog队列的大小问题,但是,它是如何初始化的呢?
ipv4协议族中listen函数的内部运行机制
利用sysctl值(SOMAXCONN)限制backlog大小之后,下一步是将侦听任务交给协议族的相关函数(inet_listen)来完成。
这一过程,具体如下图所示。
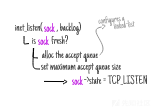
为了提高可读性,这里已经对TCP Fast Open的代码进行了相应的处理,下面是inet_listen函数的实现代码:
int
inet_listen(struct socket* sock, int backlog)
{
struct sock* sk = sock->sk;
unsigned char old_state;
int err, tcp_fastopen;
// Ensure that we have a fresh socket that has
// not been put into `LISTEN` state before, and
// is not connected.
//
// Also, ensure that it's of the TCP type (otherwise
// the idea of a connection wouldn't make sense).
err = -EINVAL;
if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM)
goto out;
if (_some_tcp_fast_open_stuff_) {
// ... do some TCP fast open stuff ...
// Initialize the necessary data structures
// for turning this socket into a listening socket
// that is going to be able to receive connections.
err = inet_csk_listen_start(sk, backlog);
if (err)
goto out;
}
// Annotate the protocol-specific socket structure
// with the backlog configured by `sys_listen` (the
// value from userspace after being capped by the
// kernel).
sk->sk_max_ack_backlog = backlog;
err = 0;
return err;
}
完成某些检查后,inet_csk_listen_start开始侦听套接字的变化情况,并对连接队列进行赋值:
int inet_csk_listen_start(struct sock *sk, int backlog)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
// Initializes the internet connection accept
// queue.
reqsk_queue_alloc(&icsk->icsk_accept_queue);
// Sets the maximum ACK backlog to the one that
// was capped by the kernel.
sk->sk_max_ack_backlog = backlog;
// Sets the current size of the backlog to 0 (given
// that it's not started yet.
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
// Marks the socket as in the TCP_LISTEN state.
sk_state_store(sk, TCP_LISTEN);
// Tries to either reserve the port already
// bound to the socket or pick a "random" one.
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
err = sk->sk_prot->hash(sk);
if (likely(!err))
return 0;
}
// If things went south, then return the error
// but first set the state of the socket to
// TCP_CLOSE.
sk->sk_state = TCP_CLOSE;
return err;
}
现在,我们已经为套接字设置了一个地址、正确的状态集和一个为传入的连接进行排序的队列,接下来,我们就可以接收连接了。
不过,在此之前,先让我们来了解一下可能会遇到的一些情况。
如果侦听之前没有执行绑定操作的话,会出现什么情况
如果“根本”没有执行绑定操作的话,listen(2)最终会为你选择一个随机的端口。
为什么会这样呢?如果我们仔细考察inet_csk_listen_start用来准备端口的方法(get_port),我们就会发现,如果底层套接字没有选择端口的话,它会随机选一个临时端口。
/* Obtain a reference to a local port for the given sock,
* if snum is zero it means select any available local port.
* We try to allocate an odd port (and leave even ports for connect())
*/
int inet_csk_get_port(struct sock *sk, unsigned short snum)
{
bool reuse = sk->sk_reuse && sk->sk_state != TCP_LISTEN;
struct inet_hashinfo *hinfo = sk->sk_prot->h.hashinfo;
int ret = 1, port = snum;
struct inet_bind_hashbucket *head;
struct inet_bind_bucket *tb = NULL;
// If we didn't specify a port (port == 0)
if (!port) {
head = inet_csk_find_open_port(sk, &tb, &port);
if (!head)
return ret;
if (!tb)
goto tb_not_found;
goto success;
}
// ...
}
所以,如果您不想在侦听的时候选择端口的话,那就随您便吧!
当接收连接的速度不够快时,哪些指标会达到峰值
假设套接字进入被动状态时,我们总是有两个队列(一个队列用于那些尚未完成三次握手的连接,另一个用于那些已经完成但尚未被接收的队列),我们可以想象 ,一旦接收连接的速度跟不上的话,第二个队列将逐渐被塞满。
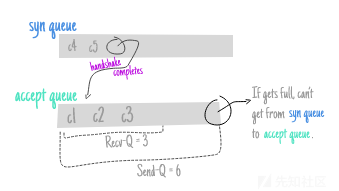
我们可以看到的第一个指标是我们之前已经介绍过的指标,即sock_diag为特定套接字报告的idiag_rqueue和idiag_wqueue的值。
idiag_rqueue
对于侦听套接字:挂起连接的数量。
对于其他套接字:传入队列中的数据量。
idiag_wqueue
对于侦听套接字:积压长度。
对于其他套接字:可用于发送操作的内存量。
虽然这些对于每个套接字的分析来说非常有用,但我们可以查看更高级别的信息,以便从整体上了解该机器的接收队列是否将出现溢出情况。
鉴于每当内核尝试将传入请求从syn队列转移到接收队列并失败时,它会在ListenOverflows上记录一个错误,所以,我们可以跟踪错误的数量(您可以从/proc/net/netstat中获取该数据):
# Retrieve the number of listen overflows # (accept queue full, making transitioning a # connection from `syn queue` to `accept queue` # not possible at the moment). cat /proc/net/netstat cat /proc/net/netstat TcpExt: SyncookiesSent SyncookiesRecv ... ListenOverflows TcpExt: 0 0 ... 105 ...
当然,我们可以看到,/proc/net/netstat提供的数据的格式不够人性化。这时,netstat(工具)就有了用武之地了:
netstat --statistics | \
grep 'times the listen queue of a socket overflowed'
105 times the listen queue of a socket overflowed
想知道内核代码中发生了什么吗? C详见tcp_v4_syn_recv_sock。
/*
* The three way handshake has completed - we got a valid synack -
* now create the new socket.
*/
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
bool *own_req)
{
// ...
if (sk_acceptq_is_full(sk))
goto exit_overflow;
// ...
exit_overflow:
NET_INC_STATS(
sock_net(sk),
LINUX_MIB_LISTENOVERFLOWS); // (ListenOverflows)
}
现在,如果syn队列接近满载,但是仍然没有出现三方握手已经完成的连接,所以不能将连接转移到接收队列,假设该队列眼看就要溢出了,那该怎么办呢?
这时,另一个指标就派上用场了,即TCPReqQFullDrop或TCPReqQFullDoCookies(取决于是否启用了SYN cookie),详情请参见tcp_conn_request。
如果想知道某时刻第一个队列(syn队列)中的连接数是多少,我们可以列出仍处于syn-recv状态的所有套接字:
# List all sockets that are in # the `SYN-RECV` state towards # the port 1337. ss \ --numeric \ state syn-recv sport = :1337
关于该主题,在CloudFlare上有一篇很棒的文章:SYN packet handling in the wild。
大家不妨去看看吧!
小结
如果能够理解为接收新连接而设置服务器TCP套接字所涉及的一些边缘情况的话,自然是极好的。所以,我计划对这个过程中涉及的其他一些内容做进一步的解释,以便帮助读者理解现代的TCP的一些怪癖行为,但那是另一篇文章的任务。最后,祝大家阅读愉快!
参考资料
- Systems Performance: Enterprise and the Cloud
- Computer Networking: A top-down approach
- The Linux Programming Interface
- Understanding the Linux Kernel, 3rd Ed
转自:https://xz.aliyun.com/t/3095