ZMap:https://zmap.io
里面有研究论文和2013USENIX安全大会的演讲稿
解释点解ZMap为嘛so fast:http://www.zhihu.com/question/21505586/answer/18443313
Nmap:http://nmap.org/
互联网扫描行为一般同僵死网络和蠕虫病毒关联在一起,但其对于安全研究也是一个非常有价值的方法。
ZMap主要就是非常快,核心优化包括:
1. 探测优化,跳过TCP/IP协议栈,另外目标地址随机分散化以保证目标路径不会拥塞。
2. 不维护跟踪每个探测的连接状态,使用一个(cyclic multiplicative group)来随机选择目标地址
3. 不重传,不保存状态,每个目标都是固定的探测包数目(缺省是1个),所以也就没有什么重传
地址探测:
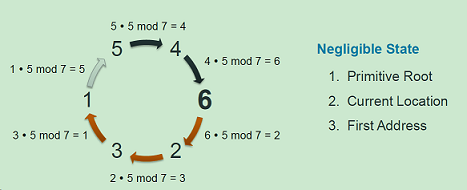
如果简单按顺序探测整个IPv4的地址,目标网络过载的风险很高.所以选择了一种随机排列的方式去遍历整个地址空间(这个也是ZMap的主要创新之一)。对于IPv4地址空间,模p值应大于2^32。
包传输和接收:发送不用完整建立TCP会话,以太网头部内容固定,避免内核路由查找,arp查找等等;接收包使用libpcap实现(绝大多数主机是不会响应探测的,所以libpcap可以处理),去除明显不是探测响应包的,然后将包传给探测模块。
探 测模块:检查响应完整性(这个应该也是ZMap的主要创新之一),有点类似SYN 的cookie机制来识别响应包,对每个扫描的主机,ZMap都依据特定的扫描密钥计算目标地址的MAC,这个MAC值则分散在主动探测模块里的任何可用 字段。TCP端口探测,使用源端口和序列号;ICMP则使用ICMP识别码和序列号。
输出模块:… …
转自:http://blog.sciencenet.cn/blog-664616-718856.html
ps:为了防止目标网络过载,zmap地址探测部分利用 本原根*IP地址数值 mod p 来生成随机的IP地址。其中,p是比2^32大的最小素数,即2^32+15=4294967311,其中3经过测试为p(4294967311)的本原根。1、prime 质数,素数
2、primitive root 本原根
这种状态记录量是巨大的,占用内存和CPU资源很大。
而ZMap索性就不进行三次握手,只进行第一个SYN,然后等待对方回复SYN-ACK,之后即RST取消连接。这样肯定会因网络原因丢失一定比例的数据,根据其实验,这个比例在2%左右。
以上策略,在nmap中也有实现,即其TCP SYN扫描方式。
关键性的问题出现在对回复的SYN-ACK进行seq number的校验。传统上就需要记录状态。
而ZMap是将对方receiver ip地址进行hash,将其处理保存到了sender port和seq number两个字段中,当SYN-ACK回来的时候,就可以根据sender ip、receiver port、ack number这些字段进行校验。
因此避免了状态存储,接近了网络带宽极限。

性能方面:
单台服务器,扫描整个IPv4地址空间,耗时45分钟,将所接1Gb的带宽占用了97%。
 不仅速度上比Nmap(TCP SYN模式)高不少,而且其设计的无状态机制,让其搜索成功的覆盖率也增加了。
不仅速度上比Nmap(TCP SYN模式)高不少,而且其设计的无状态机制,让其搜索成功的覆盖率也增加了。
与Nmap等已有系统对比:
NMap是一个通用网络监测工具,可以适用于不同协议、不同范围的测试。
而ZMap专做单端口、大范围的网络监测。
这也让ZMap能在这单一领域做很多优化。

https://zmap.io/paper.pdf
转载请注明:jinglingshu的博客 » ZMap原理